The Software Development Lifecycle (SDLC) Is Collapsing in Data Engineering
When your Jira or Linear ticket is the prompt that generates the code, why maintain separate stages?

Kaustav Mitra
·
5
min read

There's a mental model that every analytics engineering team carries around, even if they've never drawn it on a whiteboard. It goes like this: someone writes a ticket. Someone else picks it up. They read the spec, open the IDE, write the SQL, test it locally, push a branch, open a PR, wait for review, get feedback, iterate, merge, deploy, monitor. Each stage has its own tool, its own context switch, its own latency. The whole thing takes days. Sometimes weeks. And everyone involved treats it as normal — the way things have always been done.
It's not normal. It's a historical accident. And it's ending.
Four Eras in Ninety Seconds
If you compress the history of data engineering into a timeline, you get four distinct phases, each shorter than the last.
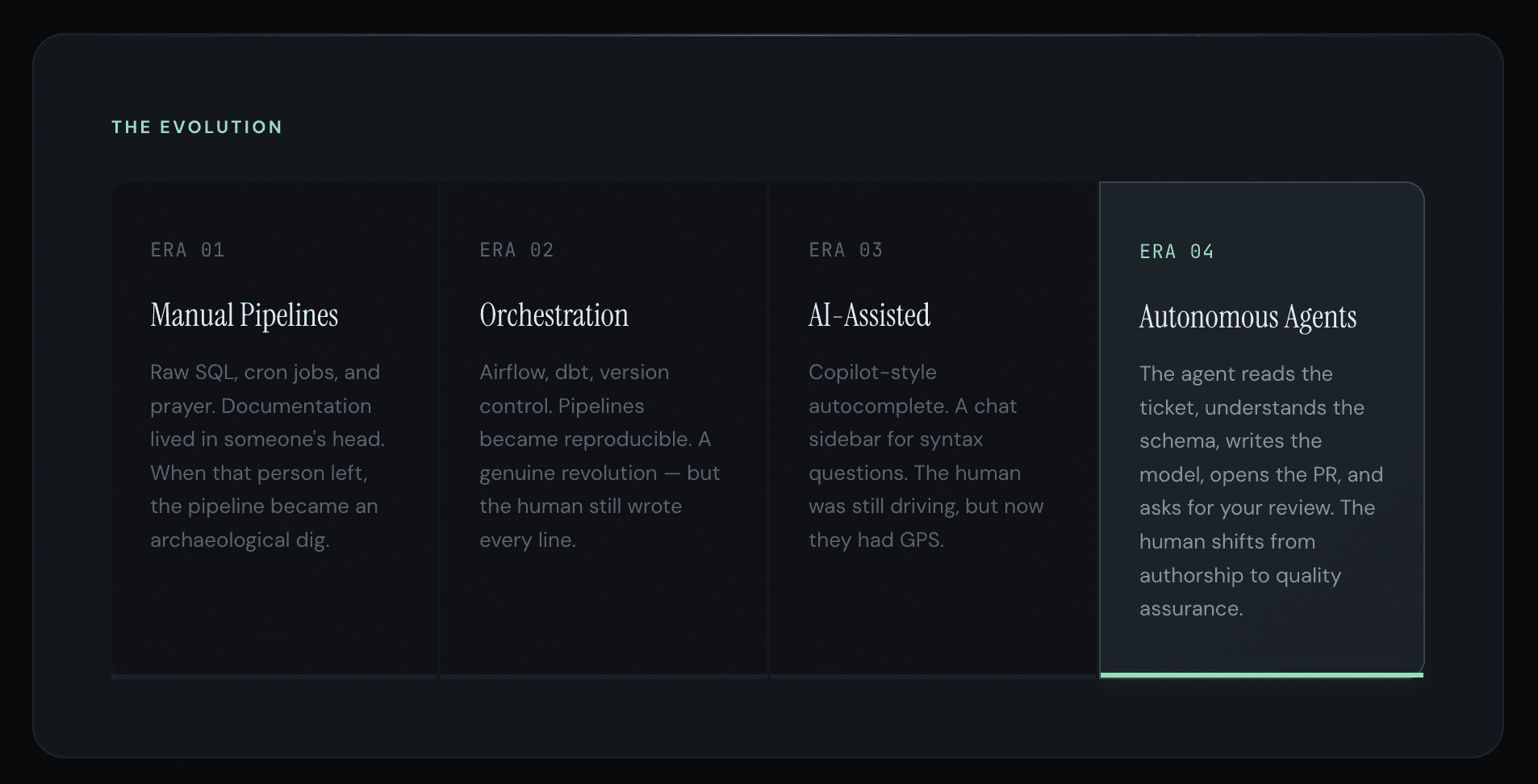
We are at the threshold of Era 4. Most teams are still operating in Era 3. That gap is about to become a canyon.
The SDLC Didn't Shrink. It Collapsed.
Here's what the traditional data engineering workflow looks like if you're honest about it — eleven discrete stages, each involving a context switch, each costing between fifteen and thirty minutes of cognitive recovery time. A single dbt model change can touch six different tools and take two days to ship.
Now here's what happens when the ticket is the prompt:
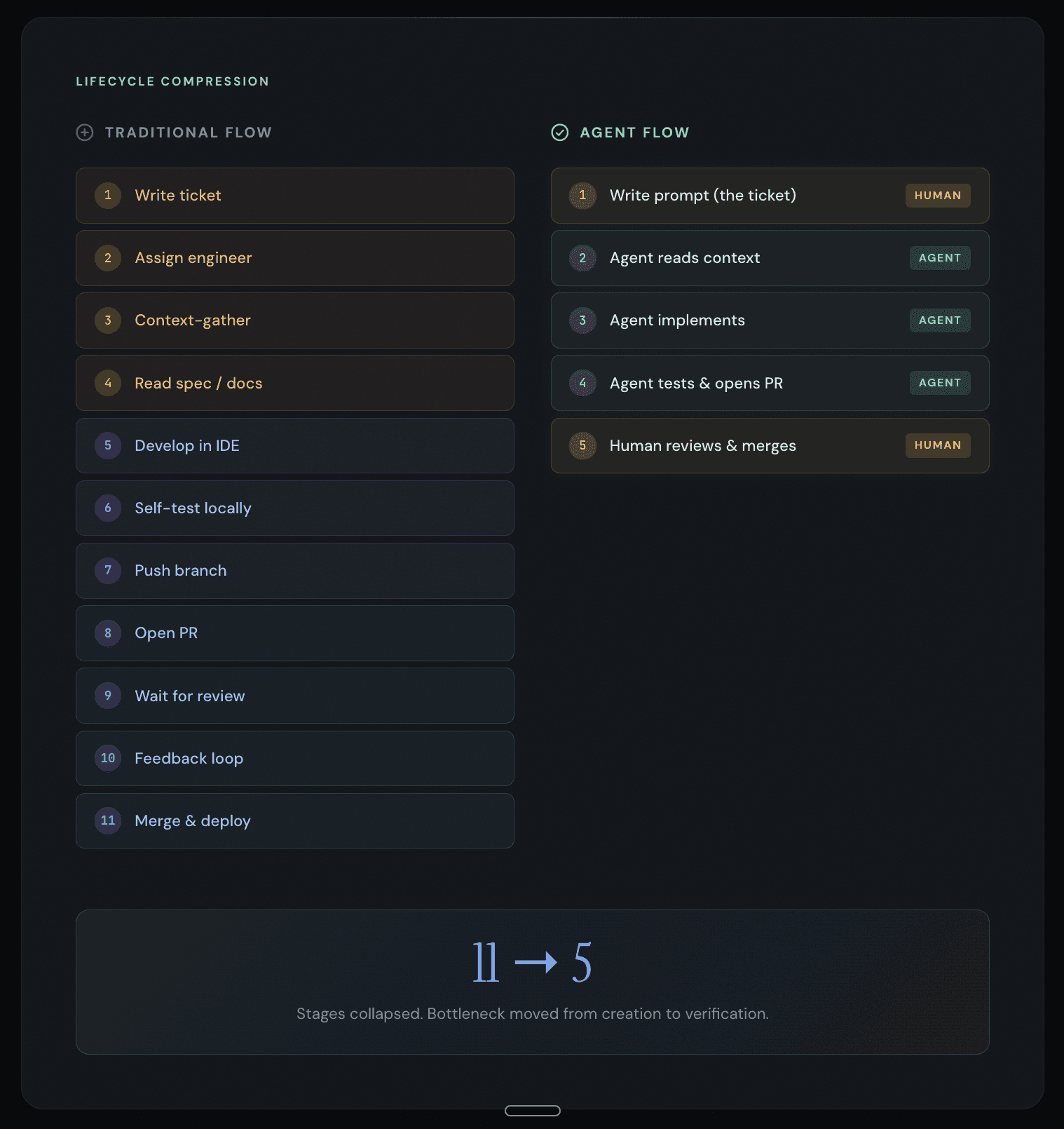
Six stages collapsed. But more importantly, the three most time-consuming stages — context-gathering, development, and self-testing — are now handled by a system that doesn't lose context, doesn't need coffee, and doesn't get pulled into a Slack thread about the office kitchen.
The bottleneck moved. It used to be "how fast can a human write code." Now it's "how fast can a human verify that code is correct." And that second question has a very different answer, because verification is cognitively cheaper than creation.
The Ticket-as-Prompt Isn't a Metaphor. It's an Architecture.
This is where most "AI for data" conversations go sideways. People treat the idea of a ticket becoming a prompt as a cute analogy. It's not. It's a literal description of how autonomous agents work when they're properly integrated.
Consider what happens when you connect an agent to your project management tool — Linear, Jira, Asana, whatever your team uses. The ticket contains structured information: a title, a description, acceptance criteria, sometimes linked specs or Notion pages. That's not just context for a human. It's a specification that a sufficiently capable agent can execute against.
The agent reads the ticket. It reads the linked Notion page with the technical spec. It examines the data warehouse schema. It checks the existing dbt project structure, naming conventions, and testing patterns. It builds the model, generates the YAML, writes the tests, validates everything against the warehouse, and opens a pull request — all without a human touching a keyboard.
This isn't science fiction. This is documentation-driven development where the documentation layer and the execution layer share the same context. The information loss between "what we want" and "what we built" approaches zero.
Why Most "AI-Assisted" Tools Miss the Point
The market is flooded with AI coding assistants. Every IDE has a chat panel now. You can ask a question, get a snippet, paste it in. That's Era 3. It's useful. It's also table stakes.
The problem with Era 3 tools is that they optimize the wrong thing. They make writing faster. But writing was never the bottleneck in analytics engineering. The bottleneck is the space between systems — the gap between the Notion spec and the IDE, between the Jira ticket and the branch, between the Slack conversation where someone said "we need to add region to the revenue model" and the PR where that change actually ships.
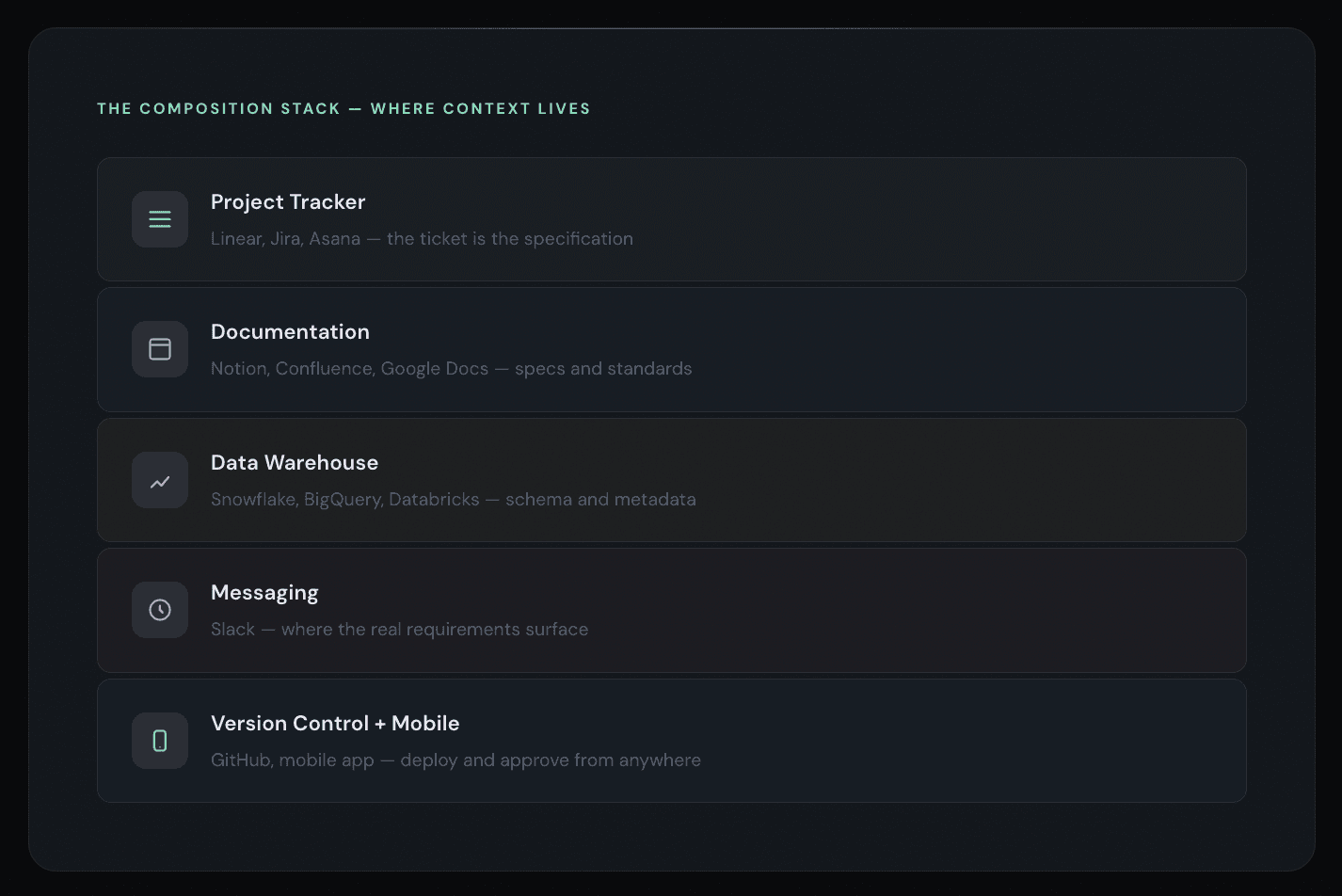
Era 4 tools don't optimize writing speed. They eliminate the translation step entirely. They operate across the surfaces where work actually happens — your project tracker, your documentation platform, your messaging app, your version control system — and they treat all of those as a single, continuous context.
This is the difference between a tool that helps you write code faster and a platform that turns intent into deployed code. One is a feature. The other is an architecture.
What the Human Actually Does Now
If the agent handles implementation, what's left for the engineer?
More than you'd think. And arguably more valuable than what they were doing before.
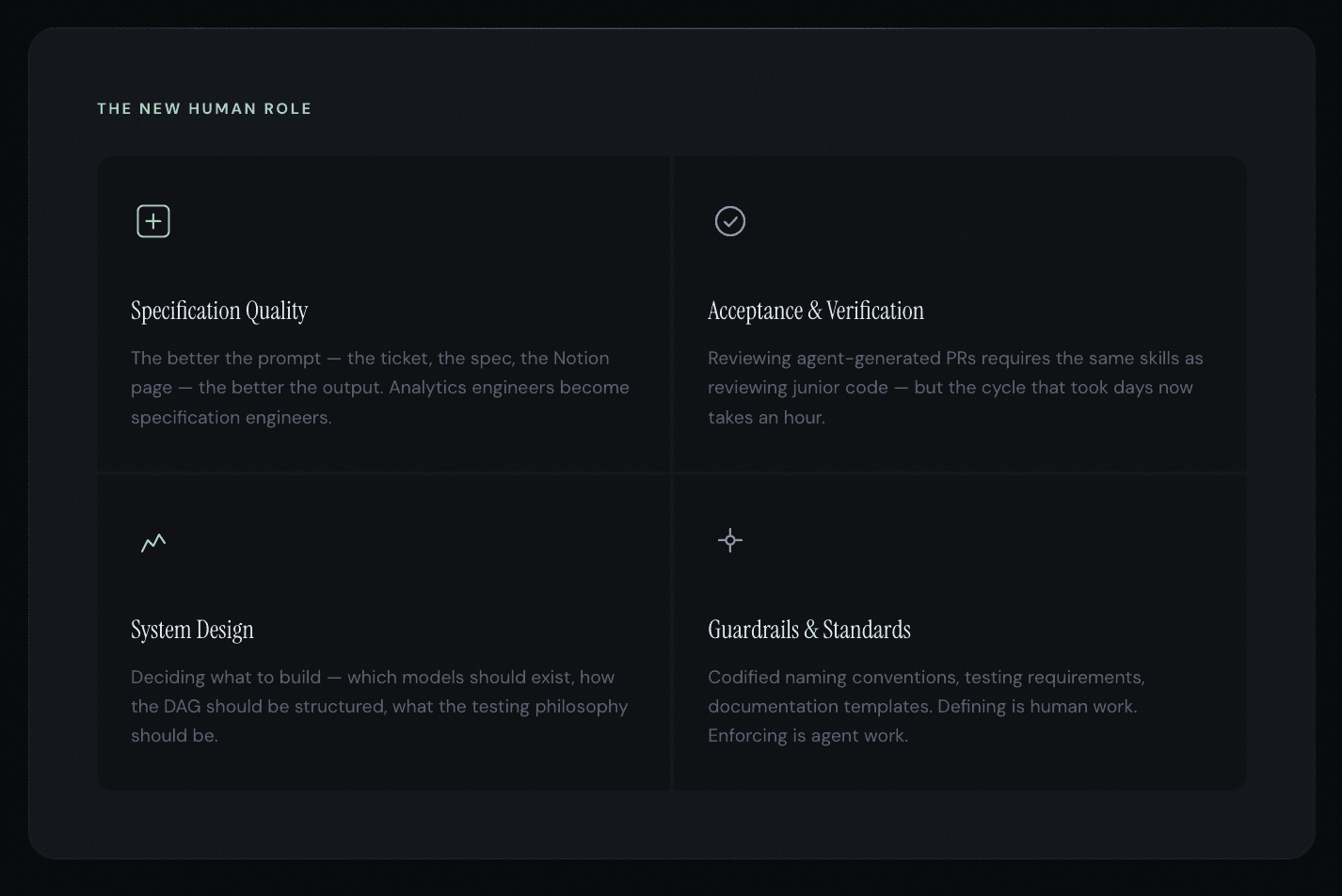
The net effect is that the human moves up the stack. Less time fighting syntax. More time thinking about whether the system is right.
The Composition Problem
Here's the part that separates the serious platforms from the demos.
Anyone can wire up an LLM to generate a dbt model. That's a weekend project. The hard part — the part that determines whether you're building a Prius or an F1 car — is the composition of tooling around the generation step.
Can the agent read your warehouse schema and understand which tables are sources, which are staging, and which are marts? Can it respect your team's naming conventions without being told every time? Can it pull context from your Notion wiki, your Jira board, and your existing codebase simultaneously? Can it open a properly formatted PR with a description that references the original ticket? Can it run the build, check for failures, and iterate before asking for your review?
Each of those capabilities is individually unimpressive. Together, they're the difference between an agent that produces throwaway snippets and one that ships production code.
And the composition has to extend beyond the IDE. Analytics engineering doesn't happen in one place. Conversations happen in Slack. Specs live in Notion or Confluence. Tickets live in Linear or Jira. Code lives in GitHub. The warehouse is Snowflake or BigQuery or Databricks. A truly autonomous agent operates across all of these surfaces, because that's where the context lives.
An agent that only works inside the IDE is an Era 3 tool wearing an Era 4 costume. The real shift happens when the agent meets you where you work.
In Slack when a pipeline breaks at 3 AM. On your phone when you need to approve a deployment. In your project tracker when a ticket is assigned.
The Acceptance Rate Is the Only Metric That Matters
When everyone has access to the same foundational models — and increasingly, everyone does — the differentiator isn't generation speed. It's acceptance rate.
How much of what the agent produces do you actually keep?
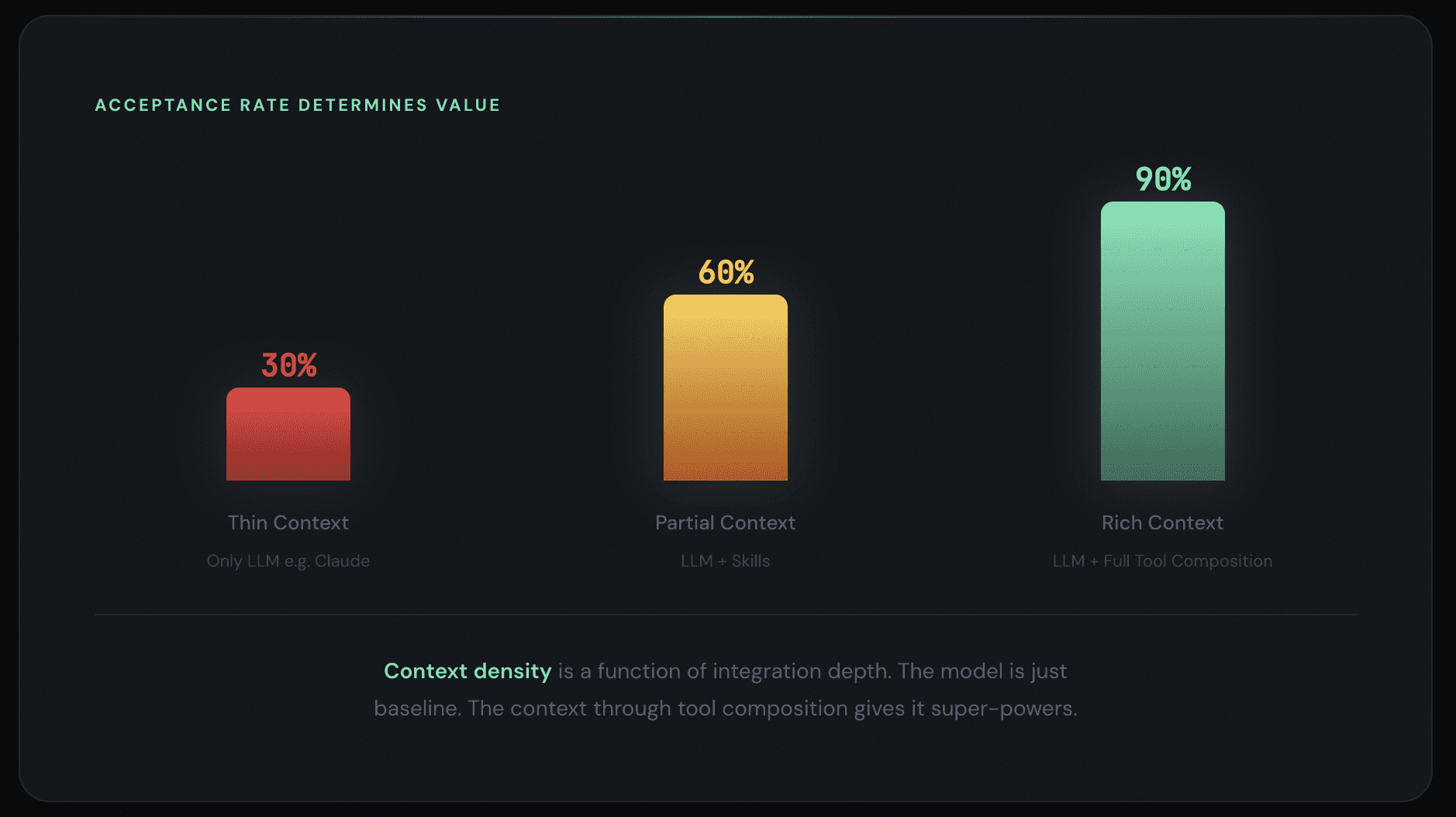
A 30% acceptance rate means the agent is generating noise that you have to sift through. You're spending more time rejecting bad output than you would have spent writing the code yourself. That's a net negative.
A 90% acceptance rate means the agent understands your context deeply enough to produce work that's right the first time. Your job becomes a quick review pass, not a rewrite. That's a 10x improvement.
The acceptance rate is a function of context density. The more the agent knows about your project — your warehouse schema, your coding conventions, your documentation standards, your business logic, your team's review preferences — the higher the acceptance rate. And context density is a function of integration depth. An agent that only sees your codebase has thin context. An agent that also sees your Notion specs, your Linear tickets, your Slack conversations, and your warehouse metadata has rich context.
This is why composition matters more than raw model capability. A frontier LLM with thin context will produce worse output than a capable LLM with rich, domain-specific context. The model is table salt. The context is the Maldon flakes.
The Window Is Open. It Won't Stay Open.
There's a pattern in technology adoption that plays out with uncomfortable regularity. A new capability emerges. Early adopters gain a compounding advantage. The majority waits for consensus. By the time consensus forms, the early adopters have built such a lead that catching up requires 10x the effort.
We're in the early-adopter window for autonomous data agents right now. The teams that learn to work with agents — that develop the muscle memory for writing good specifications, that build the guardrails and standards that make agents reliable, that restructure their workflows around human-as-reviewer instead of human-as-author — those teams will compound their advantage every quarter.
The teams that wait will find themselves in the position of the company that was still deploying manually when everyone else had CI/CD. Not dead. Just permanently behind.
The software development lifecycle is collapsing. The question isn't whether your team will adopt autonomous agents. It's whether you'll be the one setting the pace or the one trying to catch up.


