The Case for one MCP endpoint with DinoAI Context Graph
A personal setup with one MCP server per tool is a great builder's pattern. It just doesn't survive contact with the rest of the organisation. Here is why a governed gateway wins on operations and AI quality, and why it does not make any of the work you've already done redundant.

Kaustav Mitra
·
6
min read

TL;DR
A sprawl of granular MCP servers is a fine personal setup, and a difficult production one. The shift from a single engineer's stack to an organisation-wide rollout is where most MCP architectures quietly fall apart.
The operations tax compounds fast. Every joiner, every leaver, every BI tool replacement, every permissions change, and every model that flips from public to private becomes a multi-tool change request instead of a single configuration update.
The AI quality tax is just as real. Equal-weighted tools mean brute-force lookups, larger context windows, more turns to an answer, more hallucinations, and a token bill that scales fastest on premium models like Opus.
A gateway flips both. One authenticated endpoint, one access model that inherits from your data platform, and the DinoAI context graph underneath that routes the agent to the right tool in fewer turns.
It does not replace the engineering you've already done. Your
claude.mdfiles, your skills, your sub-agents, and your review patterns all still apply. DinoAI works with the same conventions you've been tuning, and gets sharper because of them.
A Builder's Setup Is Not a Production Setup
If you have wired Claude Code into Snowflake, GitHub, dbt™, Linear, and your BI tool with one MCP server each, layered sub-agents on top, and tuned a claude.md per project so the agent picks the right tool at the right time, that is real engineering. It is exactly the pattern senior and staff data engineers should be exploring. For one person who knows their stack end to end, it works.
This post is about a different question. What changes the day you decide the rest of the data team, the analytics engineers, the analysts, and the business users who never touched any of that config should get the same productivity boost?
That transition, from a tinkered personal stack to a production rollout for an organisation, is where the per-tool MCP pattern stops being clever and starts being expensive. Not because the idea is wrong, but because the operational surface area and the agent surface area both explode at the same time.
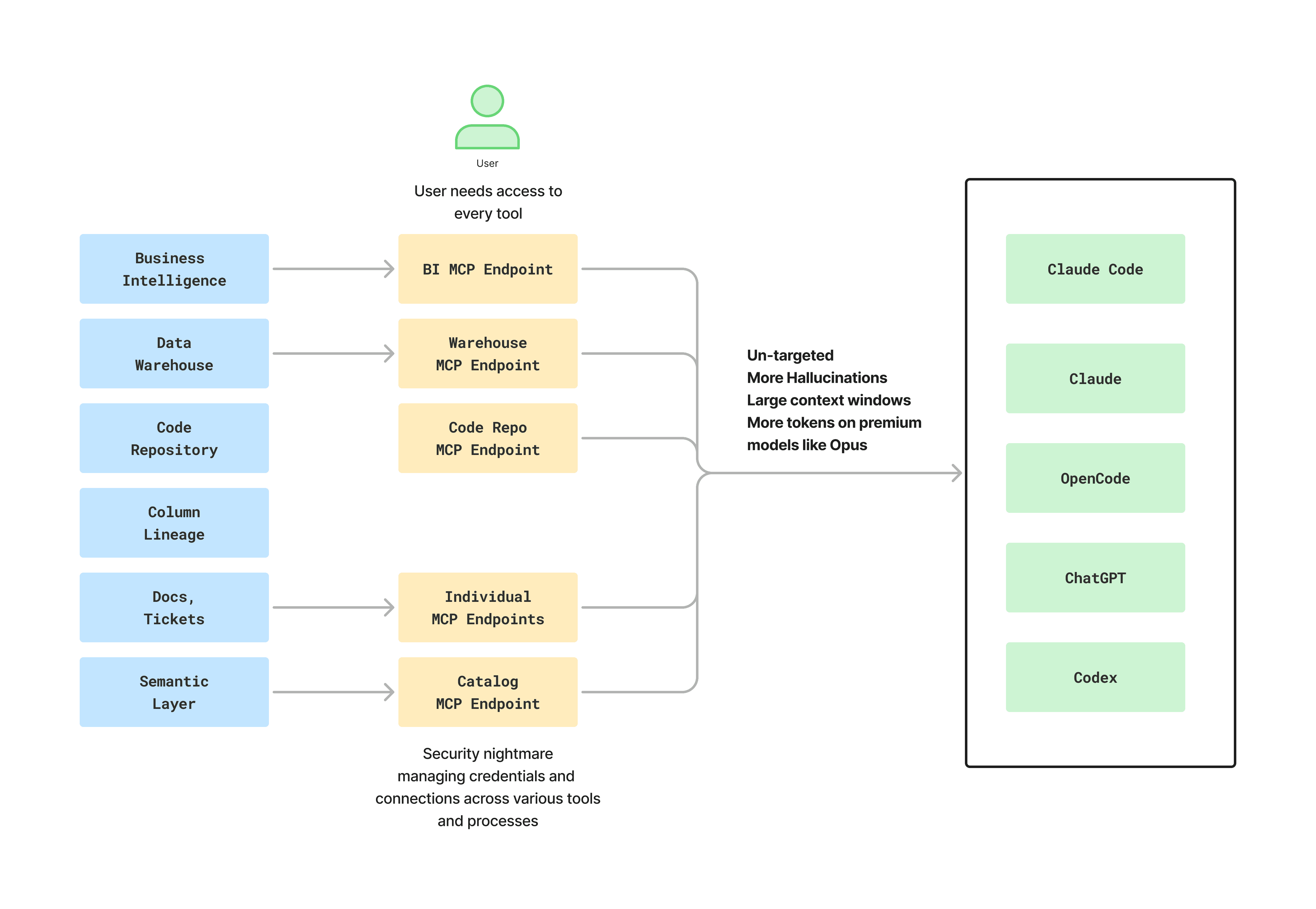
The Operations Tax
Each MCP server in a sprawl pattern carries its own identity, its own credentials, its own rotation policy, and its own permissions surface. The first few are manageable. The fifth is annoying. The tenth is a security review.
Walk through what actually happens once the rollout goes wider than the original builders:
Onboarding. Every new joiner needs warehouse access, BI access, repo access, ticket access, and a personal token for each MCP integration. Multiply that by the size of the data org and you are now running a small token-issuance program inside your team.
Offboarding. Every leaver needs the same set of credentials revoked across every tool. Miss one and an old laptop somewhere is still authenticated to your warehouse months after the person left.
Tooling changes. When the BI tool gets replaced, when the warehouse permissions model changes, when a models and business logic changes in a dbt mesh, you do not update one place. You update every client config that references that MCP, plus any sub-agent prompts that hard-coded the old shape.
Audit. "Which agent ran which query against which warehouse, on whose behalf, and was that user supposed to have access at that moment?" is a real question your security team will ask. Answering it across five disconnected MCP endpoints, each with its own log format, is painful.
Change management. Every prompt template, every sub-agent definition, every snippet of claude.md across the org has to be updated when the underlying landscape shifts. There is no single place to push a fix.
A gateway flips this. One endpoint inherits the access model you already maintain in your data platform. When a user is offboarded there, the MCP access disappears with them. When permissions change, they propagate. When the BI tool changes, the integration is swapped once and every client in the org sees the new world consistently.
This is the difference between a setup that one engineer keeps running and a system the organisation can rely on.
The Run-It Cost Nobody Plans For
There is a framing from outside the data world that is useful here. Building any internal system is roughly ten percent of the total cost. Running and supporting it is the unglamorous ninety. The build cost of wiring five MCP servers into Claude is real, but it is small. The own-it-for-a-while cost is what gets undercounted, and it shows up on someone's calendar every week of every quarter that follows.
The checklist that actually applies once an MCP sprawl leaves a single laptop and starts serving a wider team:
Production
Who is on call when an MCP server stops responding mid-pipeline at 3am?
What is the uptime expectation on each integration, and who signs up to that number?
How do you catch a broken MCP before twenty analysts file Slack tickets?
Security and compliance
Who rotates the personal access tokens across every MCP, every quarter?
When someone leaves, who confirms every MCP credential they ever issued is revoked?
Where is the audit trail that says which user, which agent, which tool, and which warehouse, at what time?
Who owns the SOC 2, GDPR, or HIPAA story for every endpoint the agent can reach?
The integration tax
When the GitHub MCP ships a breaking change, who patches the agent configs that depend on it?
When a dbt™ model flips from public to private in a mesh, who updates every prompt that referenced it?
When the BI tool is replaced next year, how many MCP configs and how many sub-agent prompts have to change?
Who maintains backward compatibility on prompts and rules, so today's working setup does not silently break next quarter?
Performance and cost
Who watches the token bill across the whole team, on premium models, every month?
Who tunes the agent so a column-lineage question does not turn into seven sequential lookups?
Docs and support
When an analytics engineer is confused about which MCP owns which capability, who answers?
Is there a runbook, or is it in one engineer's head?
People
If the engineer who set this up leaves, who picks it up?
Is the configuration written down, or is it institutional memory?
Every unchecked box is a real cost, whether you build or buy. The point is not that this work is wrong. It is that for most data teams, AI plumbing is not the edge. The edge is the analytics, the modelling, and the engineering built on top of it. When the plumbing is genuinely your edge, build it and own every box above with pride. When it is not, consuming it as a product is what frees the team to spend its time where the differentiation actually lives.
The AI Quality Tax
The second tax is on the agent itself, and it is the one that gets dismissed most often.
When you wire five granular MCP servers into a client, the model sees five sets of tools with no inherent priority between them. Ask "how does fct_orders work and what should I change for the new payments field?" and a vanilla setup will take a turn searching Linear, a turn grepping GitHub, a turn against the catalog, a turn against the warehouse, and a turn against your BI assets, often in parallel, before it does anything useful with the answers.
The visible effects are familiar to anyone who has run agents at scale:
Larger context windows on every turn, because each tool's response gets pulled back in.
More turns to a final answer, because the agent has to triangulate manually.
Higher hallucination rates, because the agent is reasoning from disconnected fragments instead of a graph.
Higher token spend, especially on Opus-class models, because both of the above multiply directly into cost.
The less visible effect is what the agent starts doing on its own initiative. We have seen well-intentioned agents alter warehouse roles, escalate privileges, and "fix" missing access by granting it. None of that is malicious. It is the natural behaviour of an agent that sees an open tool and a goal it has been told to complete.
Sub-agents help with this on the simple cases. A well-defined analytics sub-agent will route a column-lineage question more cleanly than a single monolithic agent ever will. The harder cases are where it shows. Once a question crosses two or three tools, the sub-agent still has to chain calls one at a time across granular endpoints that do not share a model of the stack. You see it as more turns. The user sees it as a slow answer. Finance sees it as an exploding token cost.
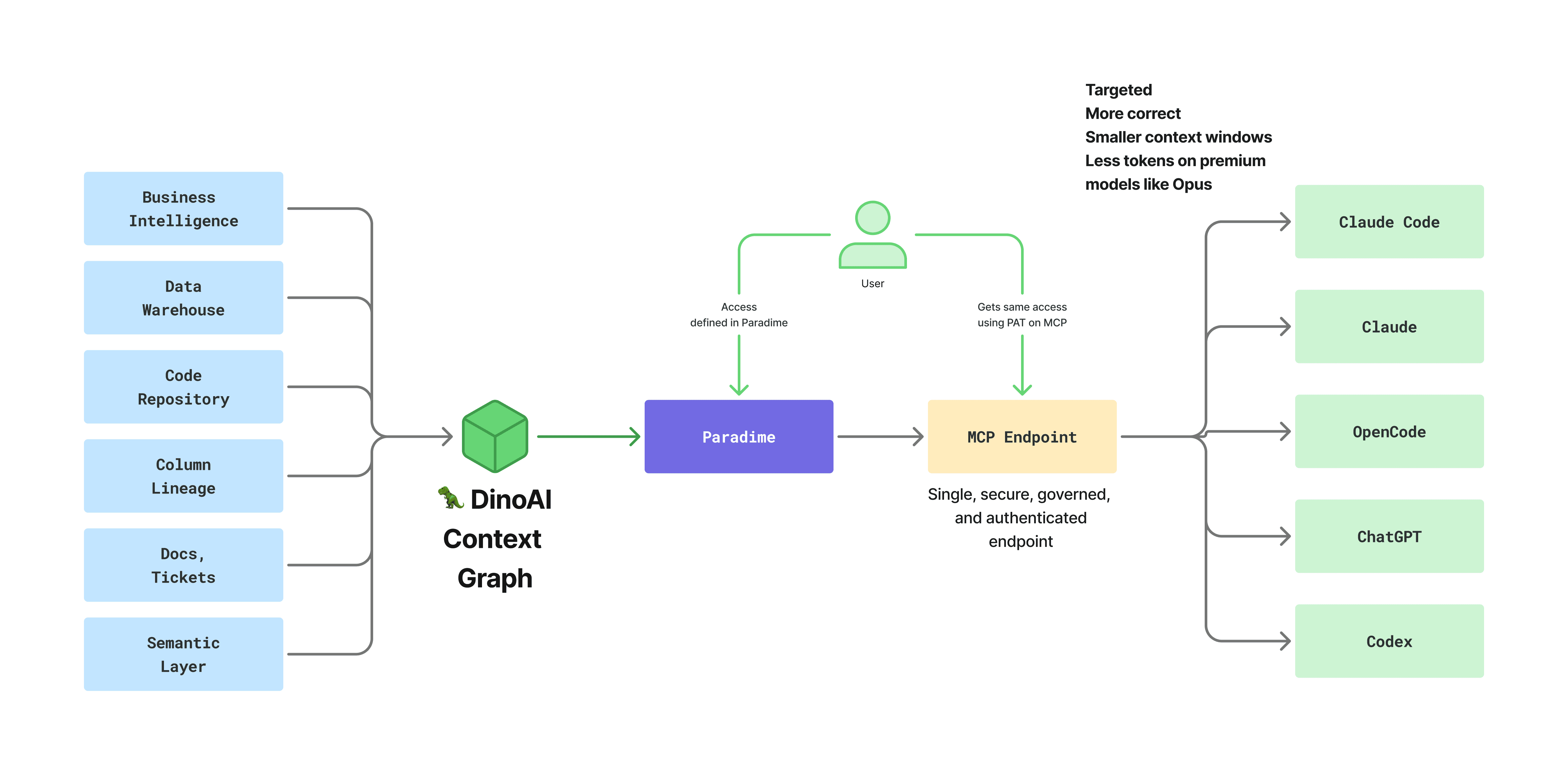
A gateway with the DinoAI context graph underneath behaves differently. A column-lineage question routes to lineage directly. A failing pipeline question routes to the orchestration logs. A semantic-layer question goes through the catalog. The agent does fewer, more targeted lookups, which means smaller context, fewer turns, and a meaningful drop in hallucinations on the questions that matter most.
"Isn't This Just a Wrapper?"
This is the question that comes up the most, and it deserves a direct answer.
A wrapper takes the APIs each MCP server exposes and routes between them. It is a thin layer of plumbing that lets one client call many backends. If that were the design, the criticism would be fair. You would be paying an extra hop for very little.
A gateway with a context graph is doing something else. The DinoAI context graph is an indexed, correlated model of your data stack. It connects your warehouse schemas to your dbt™ project, your column-level lineage to your BI assets, your orchestration runs to the tickets that triggered them, and your code repository to the catalog entries it produces. When the agent asks a question, the gateway uses that graph to route the call to the right place, in the right order, with the correlations already resolved. The agent does not have to know that lineage lives in one system and a ticket in another. It asks a question, the graph routes, and the answer comes back already joined up.
The practical difference shows up in benchmarks. The same model, given the same client, the same prompt, and the same access through a gateway with a context graph, completes more end-to-end data engineering tasks in fewer turns than the same model going through a sprawl of granular MCPs. That is not a wrapper effect. That is the difference between giving the model five disconnected toolkits and giving it one map of your stack.
What a Gateway Does Not Replace
This is the point that matters most for anyone who has already invested in a tuned multi-MCP setup, and it is worth stating clearly.
A gateway does not make the work you've already done redundant. In most cases it makes it work better. The Paradime MCP server is consumed over the standard MCP protocol, which means whichever client you point at it keeps using the conventions you have already built.
Your
claude.mdfiles still set the voice, conventions, and project-specific guardrails. When Claude Code reads itsclaude.mdand then calls the gateway for tools, the file keeps doing what it always did. The gateway is a tool surface, not an agent runtime.Your skills still apply. Skills you have already codified for Claude continue to be loaded and called the same way. The gateway provides the data and code tools the skill needs to do its job.
Your sub-agents still route. If you have built an analytics sub-agent and a data engineering sub-agent, they keep their roles. The change underneath is that they are now calling one well-typed endpoint that knows how to find the right answer, instead of five anonymous ones racing each other.
Your review and PR patterns are unchanged. The gateway does not bypass the review surface you already trust. Pull requests still go through your branch protections, your CI, and your reviewers.
Your existing tool investments stay relevant. Snowflake, dbt™, GitHub, Linear, your BI tool, your catalog. The gateway integrates with them rather than asking you to replace them.
For teams that also work inside DinoAI directly in the Paradime IDE, the same rule-and-prompt pattern carries over natively. .dinorules is the project-level rules file that sets your modelling conventions, materialization standards, SQL style, and answering style. .dinoprompts is a git-tracked YAML library of reusable prompts with template variables for things like the current git diff or the open file. They are the same shape as claude.md and your existing skill patterns, tracked in git the same way, and reviewed the same way. If your team has agreed on standards once, they are agreed everywhere.
Calling this a wrapper misses where the value is. The work you did to make Claude useful inside your stack is the work that benefits most from a context graph underneath it.
From Personal Setup to Organisational System
If you are a senior or staff data engineer running a tightly tuned multi-MCP setup that you understand end to end, keep doing that. It is the right way to learn what agents can do inside a real data stack, and the intuition you build there is exactly what an organisation needs from its senior engineers.
The argument here is narrower than "your setup is wrong." It is that the day you decide everyone else should get the same productivity boost, the problem changes shape. It becomes an operations problem and an AI quality problem at the same time, and a sprawl of granular MCPs makes both of them harder, not easier.
A governed gateway is not a substitute for the engineering you have done. It is the load-bearing layer that lets that engineering be safely used by the rest of your organisation, on the same terms, with the same guardrails, and at a quality the agent can actually deliver on.
Try the Paradime MCP Server today
Start your 14-day free trial and bring the DinoAI context graph into Claude, Claude Code, ChatGPT, and every other client your team already uses. For the architecture deep-dive and the full list of seventeen tools, read the launch announcement.

