How to Automatically Redact PII in Snowflake: Complete Guide to AI_REDACT Function
Learn how Snowflake's AI_REDACT function uses AI to automatically detect and remove PII from text data. Includes code examples, performance benchmarks, and cost analysis for GDPR/HIPAA compliance

Fabio Di Leta
·
6
min read

Handling personally identifiable information (PII) just got easier. Snowflake's new AI_REDACT function leverages LLM technology to automatically detect and redact sensitive data from unstructured text—no complex regex patterns or manual review required.
The PII Challenge in Modern Data Pipelines
Organizations today process massive volumes of unstructured text data—from call center transcripts and customer support tickets to medical records and insurance claims. This data often contains valuable insights, but it's also riddled with personally identifiable information that must be handled according to strict regulatory requirements like GDPR, HIPAA, and CCPA.
Traditional PII redaction approaches typically involve:
Complex regular expressions that miss edge cases
Manual review processes that don't scale
Rule-based systems that struggle with natural language variation
Custom ML models requiring significant maintenance overhead
Enter AI_REDACT: Snowflake's fully-managed AISQL function that uses large language models to intelligently identify and redact PII from text data.
How AI_REDACT Works
AI_REDACT is a serverless function that processes text directly within Snowflake's architecture. The function leverages an LLM hosted by Snowflake to understand context and identify PII across multiple categories—then replaces sensitive information with standardized placeholder values.
Basic Usage
The simplest implementation requires just the input text:
Output:
Notice how the function intelligently parsed the street address written in natural language ("twenty third street") without requiring structured data or predefined patterns.
Selective Redaction
For use cases where you only need to redact specific PII categories, pass an optional categories array:
Output:
This granular control allows you to balance privacy requirements with data utility—redacting only what's necessary for your specific compliance needs.
Supported PII Categories
AI_REDACT recognizes a comprehensive range of PII types, with support for US data and some UK/Canadian identifiers:
Category | Subcategories | Regional Support |
|---|---|---|
NAME | FIRST_NAME, MIDDLE_NAME, LAST_NAME | All |
ADDRESS | STREET_ADDRESS, POSTAL_CODE, CITY, ADMINISTRATIVE_AREA_1/2 | US, UK, CA |
CONTACT | EMAIL, PHONE_NUMBER | All |
DEMOGRAPHICS | DATE_OF_BIRTH, AGE, GENDER | All |
IDENTIFIERS | NATIONAL_ID (SSN), PASSPORT, DRIVERS_LICENSE, TAX_IDENTIFIER | US, UK, CA |
FINANCIAL | PAYMENT_CARD_NUMBER, PAYMENT_CARD_EXPIRATION_DATE, PAYMENT_CARD_CVV | All |
NETWORK | IP_ADDRESS | All |
The hierarchical category structure means specifying NAME will automatically redact FIRST_NAME, MIDDLE_NAME, and LAST_NAME. The output will consistently use the parent category placeholder ([NAME]) for easy downstream processing.
Real-World Implementation Pattern
Here's a production-ready pattern for processing and storing redacted data at scale:
This pattern demonstrates a key advantage of AI_REDACT: seamless integration with Snowflake's AISQL ecosystem. You can chain AI_REDACT with functions like AI_SENTIMENT, AI_PARSE_DOCUMENT, or AI_TRANSCRIBE to build complete privacy-preserving analytics pipelines.
Processing Flow Diagram
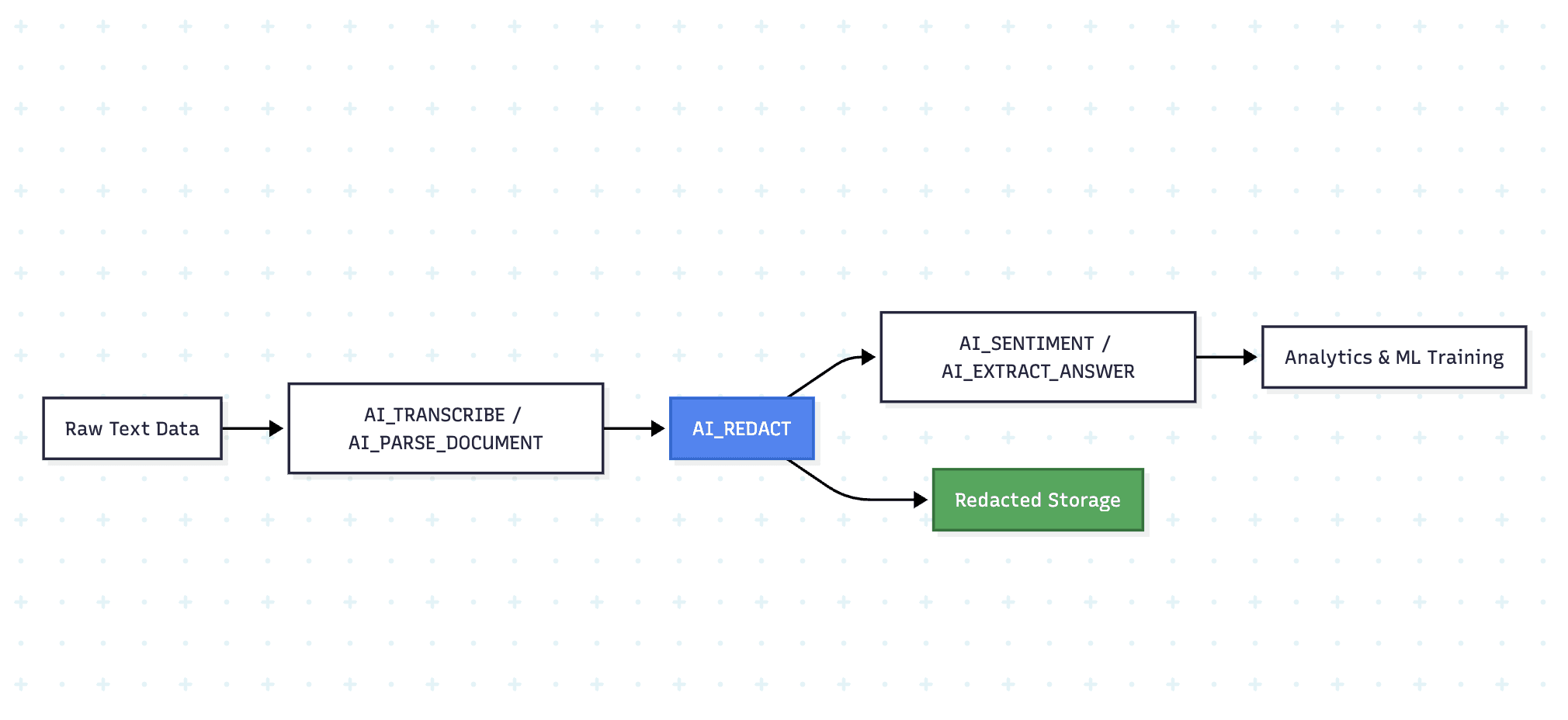
Enterprise Error Handling
When processing millions of rows, robust error handling becomes critical. AI_REDACT supports graceful degradation through Snowflake's AI_SQL_ERROR_HANDLING_USE_FAIL_ON_ERROR parameter:
This approach ensures that processing failures on individual rows don't crash your entire pipeline—critical for production data engineering workflows.
Key Considerations and Limitations
While AI_REDACT is powerful, understanding its current limitations is essential for production deployment:
Token Limits
Combined input/output: 4,096 tokens maximum
Output only: 1,024 tokens maximum
Workaround: Use
SPLIT_TEXT_RECURSIVE_CHARACTERto chunk large documents before redaction
Language and Quality
Optimized for well-formed English text
Performance may vary with other languages or text containing significant spelling/grammatical errors
Consider text quality preprocessing for optimal results
AI-Based Redaction
Critical: AI_REDACT uses best-effort redaction via LLM models. Always implement secondary validation for high-compliance environments. As stated in the official documentation:
"Always review the output to ensure compliance with your organization's data privacy policies."
For regulated industries, consider:
Sampling output for manual validation
Implementing secondary rule-based checks for known PII patterns
Maintaining audit logs of redaction operations
Testing with synthetic data that contains known PII before production deployment
Cost Optimization
AI_REDACT follows Snowflake's token-based pricing model for AISQL functions. Optimize costs by:
Pre-filtering: Remove non-textual data before calling AI_REDACT
Selective categories: Only redact necessary PII types for your use case
Batch processing: Process data in bulk rather than row-by-row
Caching: Store redacted results to avoid reprocessing static data
Refer to the Snowflake Pricing Guide for detailed token pricing information.
Use Cases in Production
AI_REDACT shines in scenarios requiring privacy-preserving analytics:
Call Center Analytics
Healthcare Data Analysis
Insurance Claims Processing
The Bigger Picture: AI-Native Data Privacy
AI_REDACT represents a shift in how we approach data privacy—moving from rigid, pattern-based systems to context-aware, AI-native solutions. This approach offers:
Semantic understanding: Recognizes PII even when expressed in non-standard formats
Lower maintenance: No regex patterns to update as data formats evolve
Faster deployment: Production-ready functionality without custom ML model development
Unified platform: Native integration with Snowflake's data and AI ecosystem
As organizations increasingly use LLMs for data analysis, having privacy controls that operate at the same semantic level becomes essential. AI_REDACT allows you to safely leverage AI throughout your data pipeline—from ingestion to insights—without compromising individual privacy.
Getting Started
AI_REDACT is currently available in Preview to all Snowflake accounts. To start using it:
Review the official documentation for regional availability
Check Regional availability for your Snowflake deployment
Test with sample data using the examples above
Implement error handling and validation for production workloads
Monitor token usage and costs as you scale


