Context Engineering and AI Quality for Data Teams
Most organizations are flying blind when it comes to AI quality and at Paradime we have been thinking how we can use context engineering and orchestration together to solve this problem.

Kaustav Mitra
·
5
min read

The data stack has evolved dramatically over the past decade. We moved from monolithic data warehouses to modern cloud platforms. We adopted dbt™️ for transformation. We built semantic layers like Cube.dev for metrics. And now, we're embedding AI into every product and process.
But here's the problem: most organizations are flying blind when it comes to AI quality.
Teams are spinning up LLMs for customer support, product recommendations, and content generation without any systematic way to measure whether these AI features are actually working. The evaluation happens manually, sporadically, or not at all. By the time quality issues surface, customers have already had poor experiences.
At Paradime, we've experienced this firsthand. As we built DinoAI - our AI-powered assistant for analytics engineering aka Cursor for Data - we quickly realized we needed a robust, automated way to evaluate AI output quality. Not as an afterthought, but as an integral part of our data pipeline.
That's why we built dbt-llm-evals, an open-source framework that brings LLM evaluation directly into your data warehouse. It's now available in the dbt package hub, and it's changing how teams think about AI quality.
The New Reality: Data Teams Are the AI Product Owners
Here's what we're seeing across the industry: data teams are fast becoming the builders and owners of AI products.
Why? Because they already own the critical ingredients:
The context: Customer behavior, product usage, business metrics - the raw material for effective AI
The infrastructure: Data warehouses with compute and AI capabilities
The workflows: Pipelines for ingestion, transformation, and delivery
The quality mindset: Testing, monitoring, and continuous improvement
The question isn't whether data teams should build AI products - they already are. The question is whether they're building them with the same rigor they apply to everything else.
And here's the secret: The best AI products aren't built by prompt engineers alone. They're built by data teams who understand context engineering - the practice of systematically building, refining, and managing the contextual data that makes AI outputs actually useful.
The Challenge: AI Evaluation Shouldn't Be an Afterthought
Here's how most teams approach AI today:
Build AI features in production
Store inference data in the warehouse
Hope for the best
Manually investigate when something seems wrong
Struggle to systematically improve quality
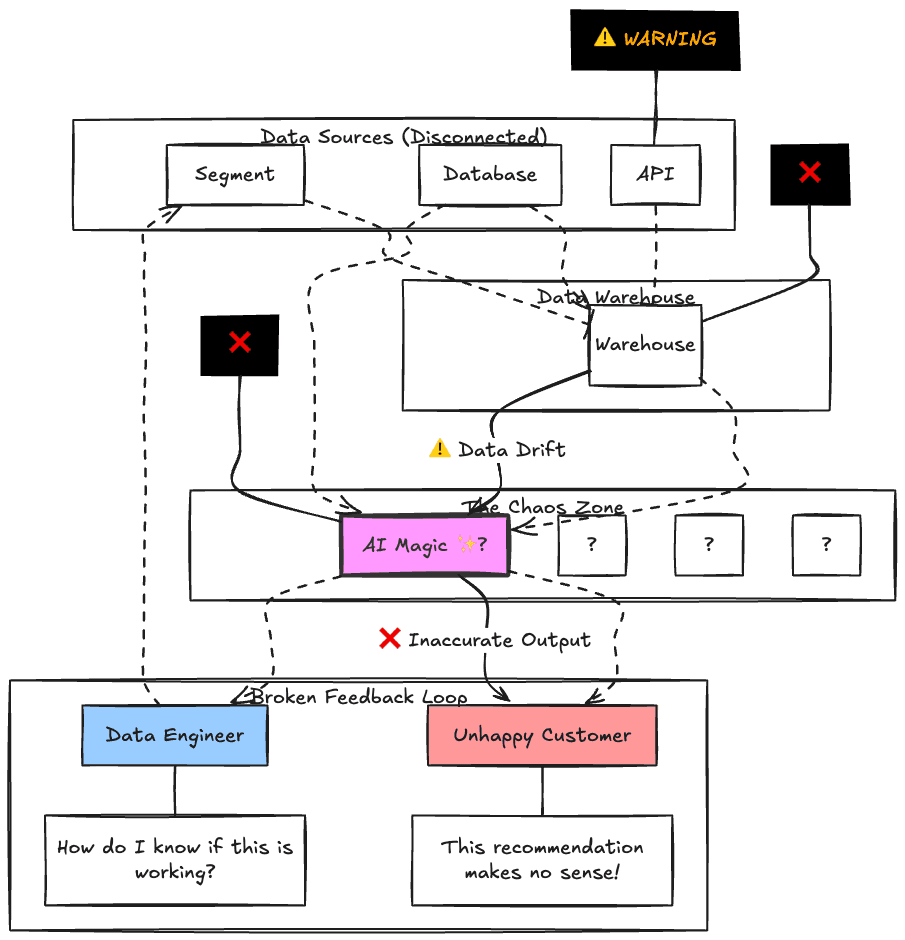
Figure 1: The Broken AI Workflow
This creates fundamental problems:
No visibility into AI performance until users complain
Slow iteration because you can't measure what's working
Inconsistent quality across different use cases
Wasted compute on low-quality inferences you can't identify
Poor context engineering—teams don't know which contextual signals improve AI quality
The root cause? Treating AI evaluation as separate from data pipelines, when it should be core to them.
A Better Way: Evaluation as Part of Your Data Workflow
What if you could ingest data, transform it, generate AI inferences, and evaluate quality—all in one unified workflow, without any additional infrastructure?
That's exactly what leading data teams are doing with Paradime Bolt and dbt-llm-evals.
The insight: Your warehouse already has everything you need. The data, the compute, the AI capabilities. You just need to orchestrate it properly—and treat context engineering as a first-class discipline alongside your AI inference and evaluation.
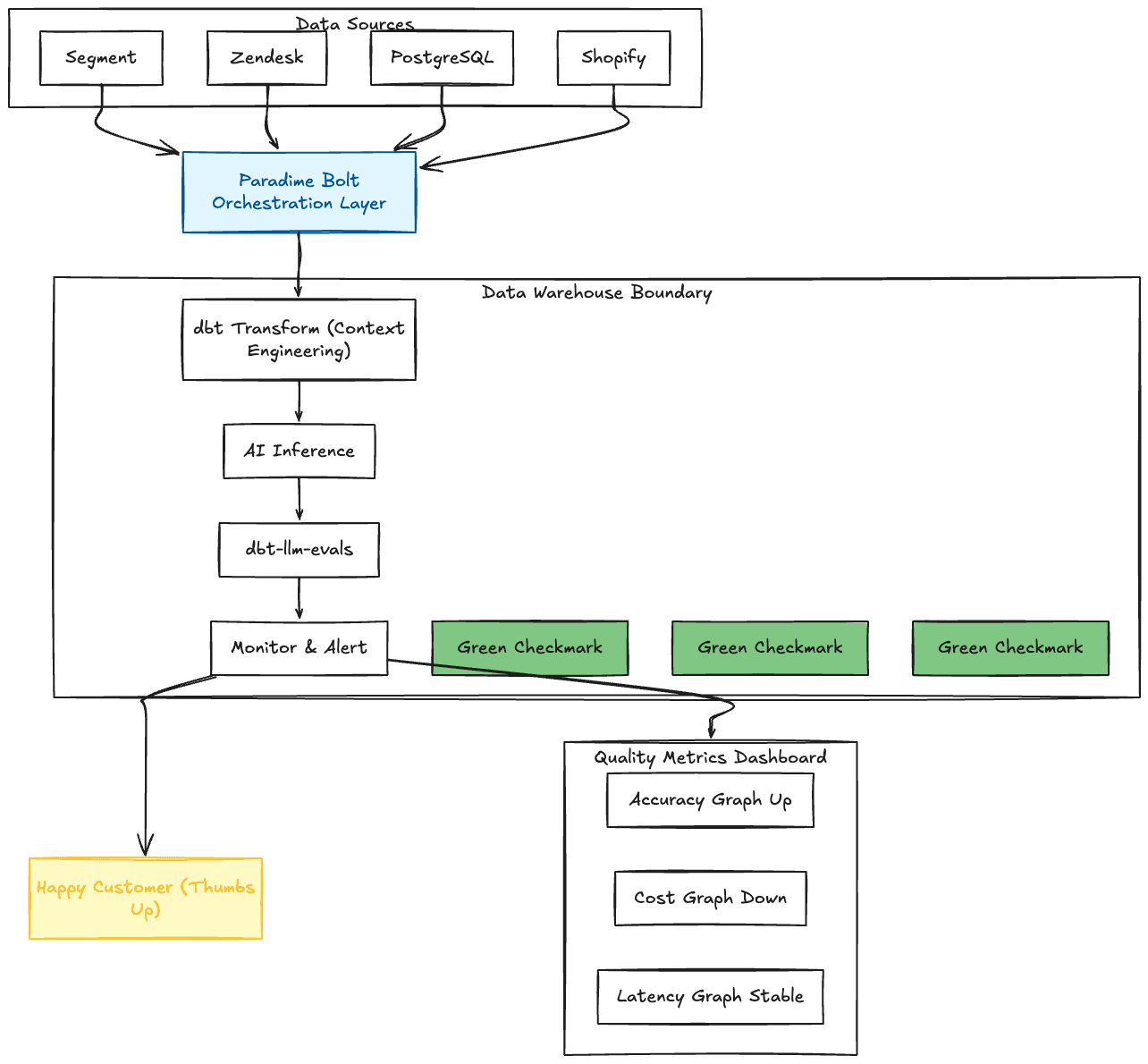
Figure 2: The Unified AI Workflow
Real-World Example: E-Commerce Product Recommendations
Let's walk through how a retail company built an AI-powered recommendation engine entirely within their existing data stack:
Step 1: Data Ingestion with Paradime Bolt
Using Paradime Bolt's built-in integrations, the team ingests data from multiple sources into their warehouse:
Customer browsing behavior from Segment
Purchase history from their operational database
Product catalog from their e-commerce platform
Customer support interactions from Zendesk
Product reviews and ratings
All of this lands in their warehouse, ready for context engineering.
Step 2: Context Engineering with dbt™️
This is where the magic happens. Context engineering is the practice of deliberately modeling and curating the contextual data that makes AI outputs relevant and valuable. It's not just data transformation - it's the strategic work of deciding which signals matter, how to combine them, and how to present them to your AI models.
They use dbt™️ to engineer rich customer context:
This is the key differentiator: Rich, well-modeled context that comes from deliberate context engineering work. You're not just passing raw data to an LLM - you're curating the exact signals that will lead to better recommendations.
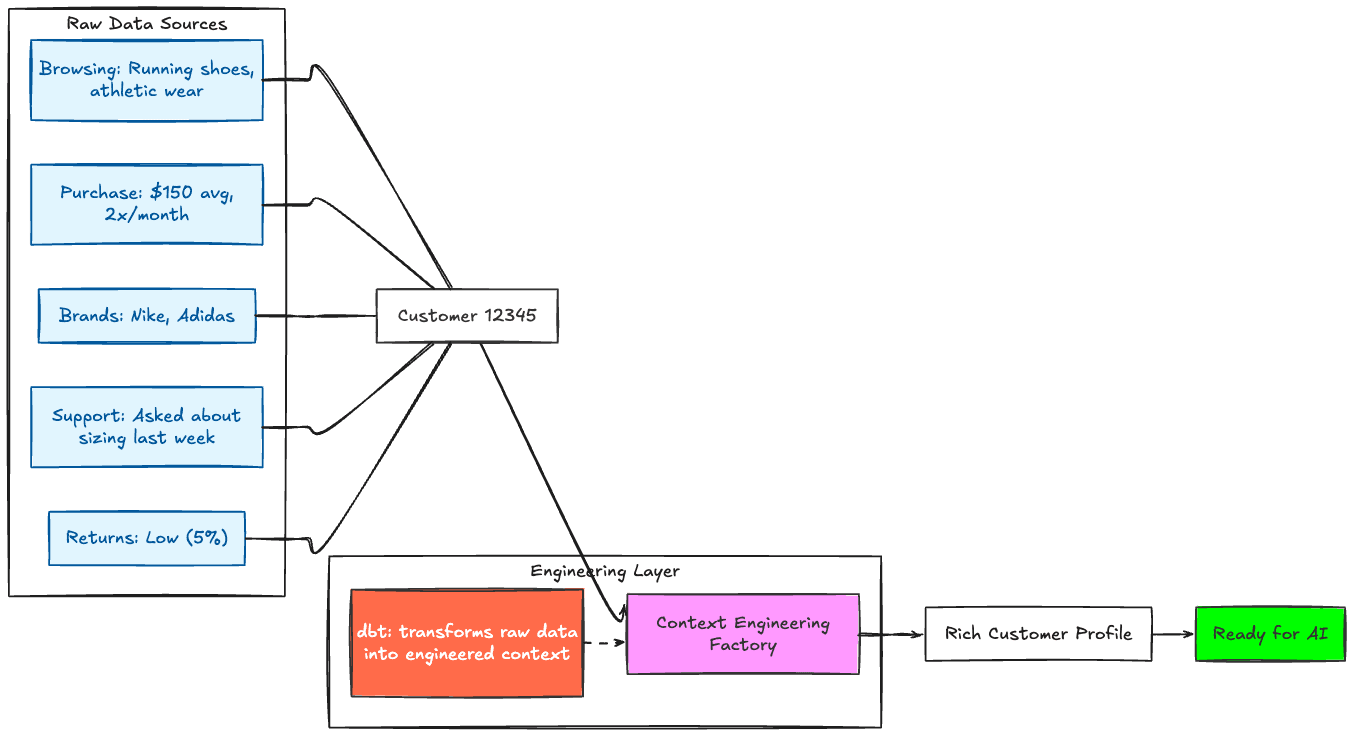
Figure 3: Context Engineering - The Foundation
Step 3: AI Inference in the Warehouse
Using native warehouse AI functions (Snowflake Cortex, BigQuery ML, or Databricks ML), they generate recommendations using the engineered context:
Notice how the engineered context flows directly into the AI prompt. This isn't accidental - it's the result of deliberate context engineering.
Step 4: Immediate Quality Evaluation with dbt-llm-evals
Here's where it gets powerful. In the same dbt run, they evaluate every single AI inference. And critically, they evaluate using the same engineered context:
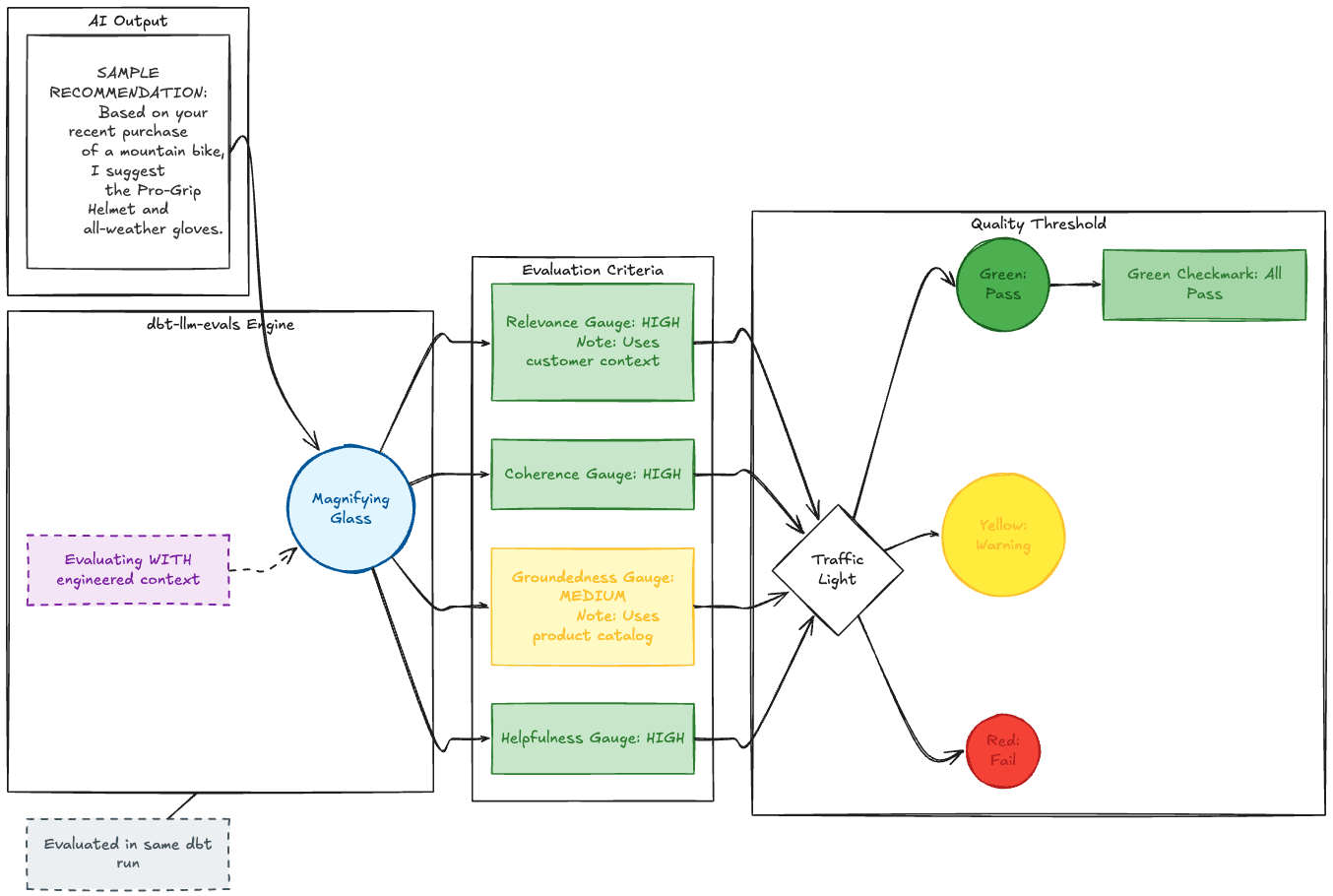
Figure 4: The Evaluation Layer
The package supports five built-in evaluation criteria, all scored on a 1-10 scale:
Accuracy: Factual correctness of the output
Relevance: Does the recommendation match customer needs and context?
Tone: Is the appropriate tone maintained?
Completeness: Are all aspects of the input fully addressed?
Consistency: Is the output consistent with baseline examples?
You configure which criteria to use globally in your dbt_project.yml:
The workflow is simple:
One-time setup:
dbt run --select llm_evals__setupcreates the evaluation infrastructureEvery model run: The post-hook captures samples and creates a baseline on first run
Evaluation:
dbt run --select tag:llm_evalsruns the judge evaluation process
The result: Every AI inference is automatically evaluated for quality using an LLM-as-a-Judge pattern—and the evaluation is context-aware because it uses the same engineered context you built.
Step 5: Continuous Monitoring and Rapid Iteration
With evaluations as part of the workflow, teams can build systematic improvement loops. This is where context engineering truly shines - you can measure which contextual signals actually improve AI quality:
Track quality trends over time:
Monitor for drift and quality degradation:
Test different context engineering approaches:
When you want to improve quality, you can version your baselines and compare:
Then compare performance:
This is the power of treating context engineering as a measurable, improvable discipline. You can A/B test different context models and see which ones produce better AI outputs.
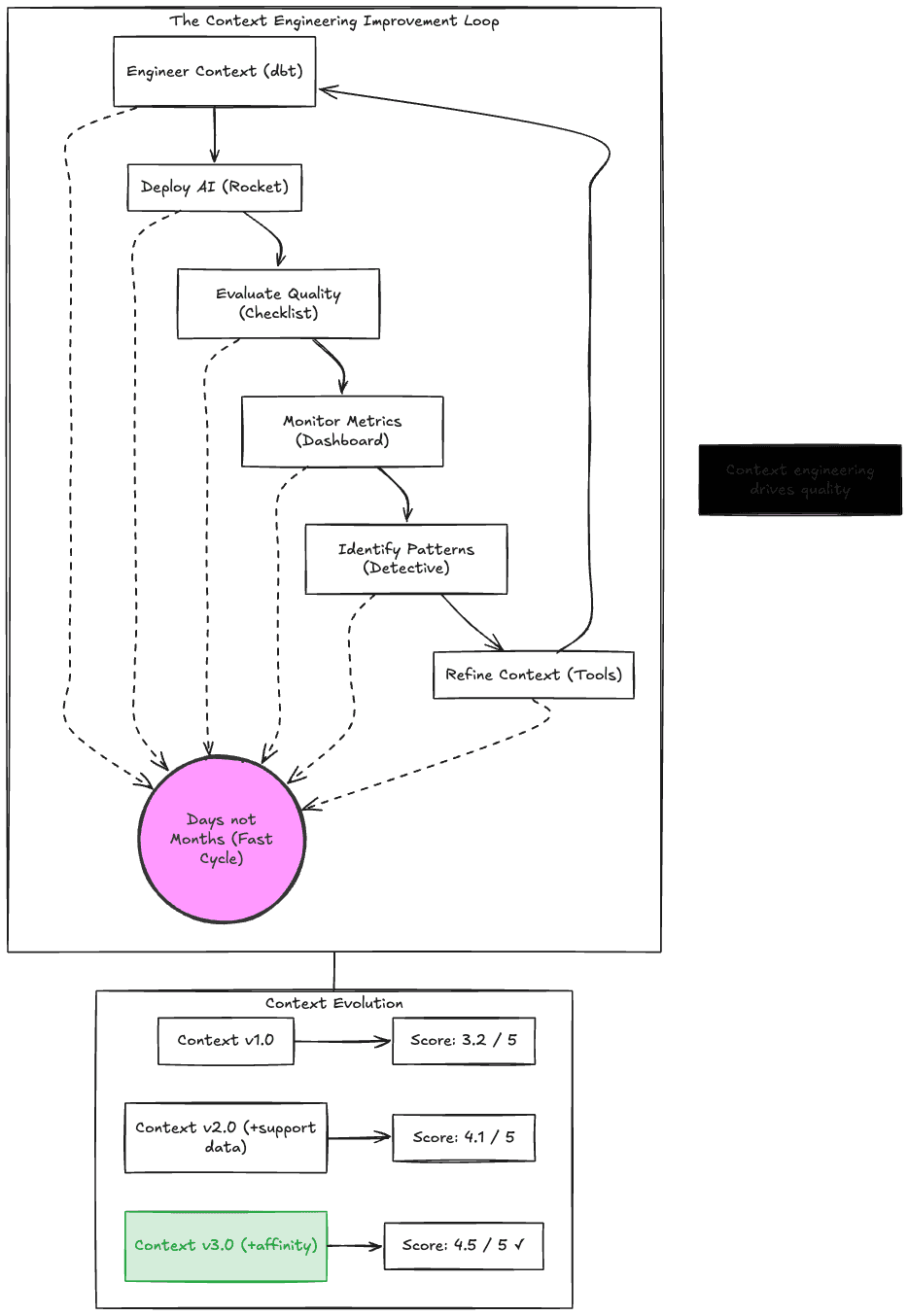
Figure 5: The Context Engineering Improvement Loop
Set up automated alerts in Paradime Bolt:
The Compound Advantage: Why This Approach Wins
When you evaluate AI quality within your data workflow, you unlock capabilities that isolated evaluation tools can't match:
1. Zero Data Movement
Everything stays in your warehouse. No egress costs, no compliance risks, no latency from data transfer.
2. Context-Aware Evaluation
You're evaluating with the same rich, engineered context you used to generate inferences. Your evaluations are smarter because they understand the full picture. This is impossible when evaluation happens in external tools that don't have access to your context engineering.
3. Single Workflow, Single Source of Truth
Data ingestion → Context engineering → AI inference → Quality evaluation → Monitoring. One pipeline. One dbt project. One deployment.
4. Fast Iteration Loops
Change your context engineering? Adjust a prompt? Re-run your dbt models and immediately see quality impact. No switching tools, no manual processes.
5. Production-Grade from Day One
Your AI evaluation inherits all the best practices from your data stack: version control, testing, documentation, lineage, observability.
6. Measurable Context Engineering
Because evaluation happens in the same workflow as context engineering, you can scientifically measure which contextual signals improve AI quality. Context engineering becomes a data-driven discipline, not guesswork.
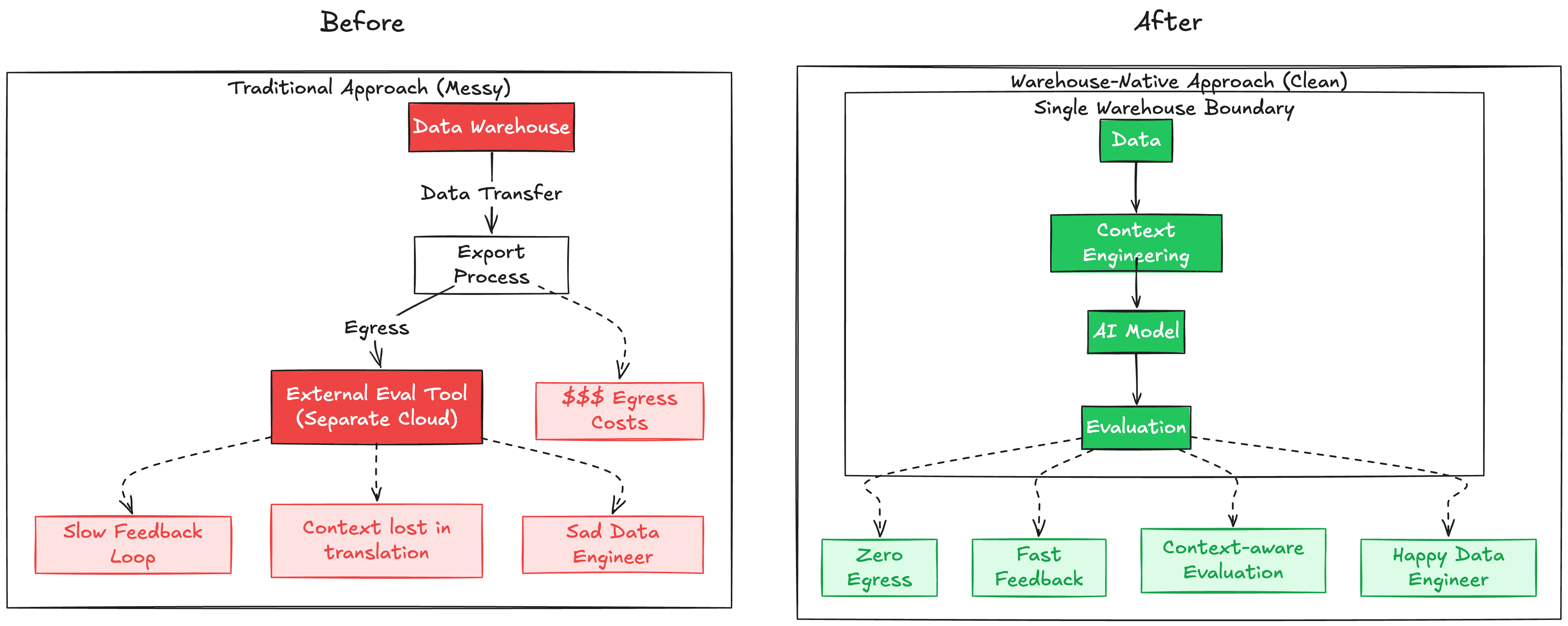
Figure 6: Traditional vs Warehouse-Native Approach
Why This Matters for Business Leaders
If you're a CxO or VP overseeing teams building AI products—whether for internal use or customer-facing features—here's what you need to know:
Your data team is already positioned to be your AI product team. They have the context, the infrastructure, and the skillset. What they need is the right framework for systematic quality management and context engineering.
Here's the reality: AI quality is directly proportional to context quality. The best prompts in the world won't save you if you're feeding your AI models poor context. And the only teams who can do world-class context engineering are data teams—because they're the only ones who truly understand your data.
Without warehouse-native evaluation, you face:
❌ Blind spots in AI quality until customers complain
❌ Data egress costs and compliance headaches
❌ Slow iteration cycles with disconnected tooling
❌ Inconsistent quality across AI use cases
❌ Difficulty proving ROI on AI investments
❌ No way to measure or improve your context engineering
With dbt-llm-evals and Paradime Bolt, you get:
✅ Real-time quality monitoring as part of your existing pipelines
✅ Single source of truth for data, transformations, inferences, and evaluations
✅ Fast, confident iteration on AI products
✅ Production-ready AI workflows from day one
✅ Clear metrics to demonstrate AI value and quality
✅ Data-driven context engineering that measurably improves AI outputs
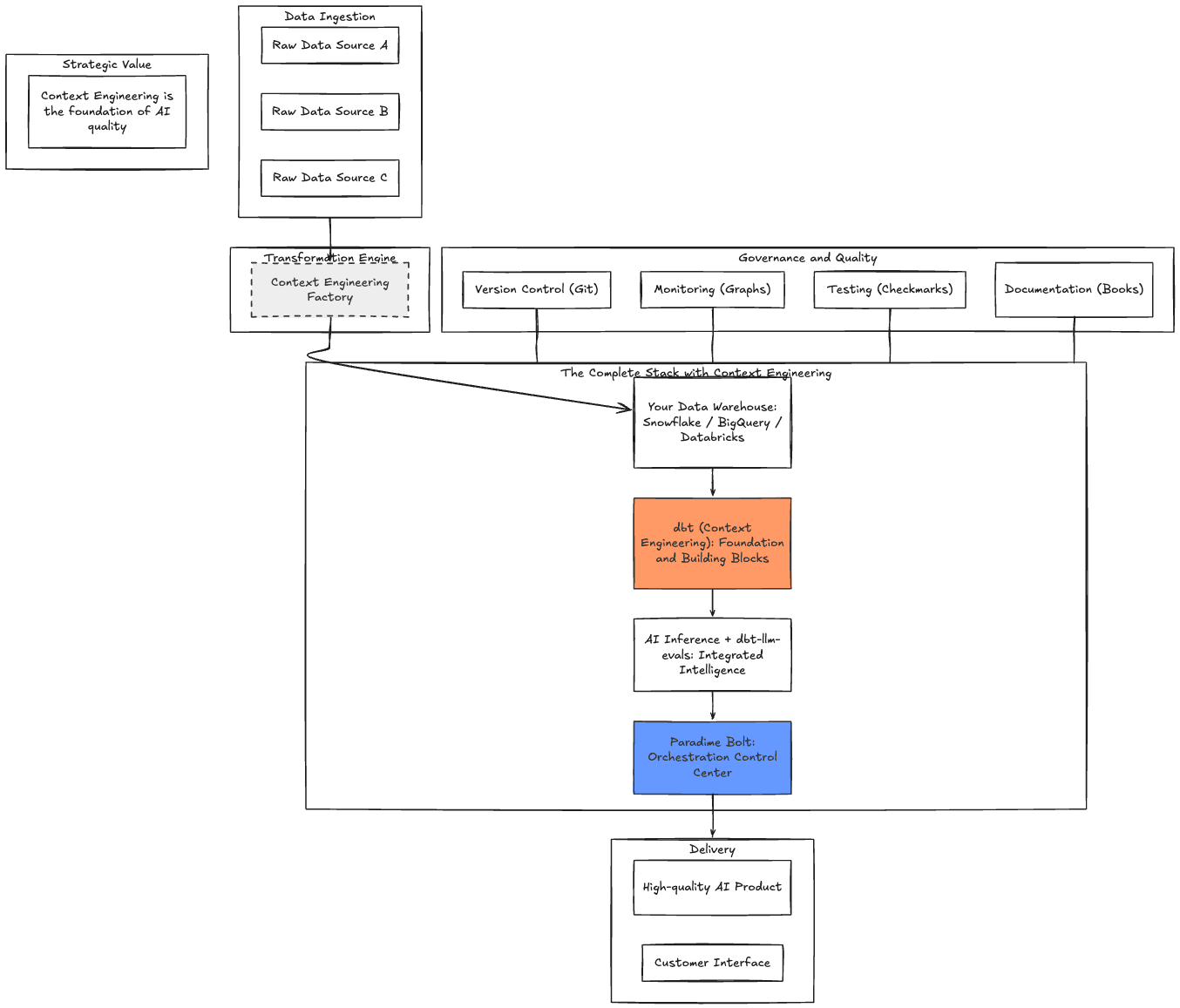
Figure 7: The Complete Stack with Context Engineering
The Context Engineering Advantage
Let's be explicit about this: context engineering is what separates great AI products from mediocre ones.
Every company has access to the same LLMs. OpenAI's GPT-4, Anthropic's Claude, Meta's Llama - they're all available via API. The differentiator isn't which model you use. It's the quality of the context you provide to those models.
Data teams are uniquely positioned to excel at context engineering because they:
Understand your data deeply
Know how to model and transform data for specific use cases
Can join signals from multiple sources
Apply data quality practices to context quality
Measure and iterate on contextual signals
When you combine strong context engineering with systematic evaluation in a unified workflow, you create a flywheel:
Engineer rich context
Generate AI inferences
Evaluate quality (using that same context)
Identify which context signals drive quality
Refine your context engineering
Repeat
This is how you build AI products that actually work.
Getting Started Today
The dbt-llm-evals package currently supports:
✅ Snowflake (via Cortex)
✅ Google BigQuery
✅ Databricks
Support for additional warehouses like Trino, Redshift, and others can be added in hours based on demand.
Ready to build AI products with systematic context engineering and evaluation?
Start with the 15-minute quickstart guide
Learn about LLM evaluation criteria
Understand the LLM-as-a-Judge approach
Explore the GitHub repository
Try Paradime Bolt to orchestrate your complete AI workflow
The Path Forward
The future belongs to data teams who treat AI products with the same rigor they apply to data products. That means version control, testing, monitoring, systematic quality evaluation, and disciplined context engineering—not as afterthoughts, but as core capabilities.
With dbt-llm-evals and Paradime Bolt, you can build that capability today. Your warehouse already has the data, the compute, and the AI. You just need to orchestrate it with intention, and treat context engineering as the strategic discipline it deserves to be.
The question isn't whether to evaluate your AI outputs. It's whether you'll do it systematically—with context-aware evaluation that drives continuous improvement—or wait until quality issues find you.
Ready to add systematic AI evaluation and context engineering to your data pipeline? Start with dbt-llm-evals today, or reach out to learn how Paradime Bolt can accelerate your entire AI development workflow.


