How We Built AI-Powered Analytics: A Practical Guide
End-to-end AI analytics architecture: ingestion, transformation, LLMs in SQL, semantic layer, orchestration. Practical guide from Paradime's stack.

Fabio Di Leta
·
8
min read

TL;DR: Built a production AI pipeline serving our customers as a “solo data team”.
Stack: PeerDB + Fivetran + dlt for ingestion, dbt™ for transformation, BigQuery + Vertex AI for native LLM execution, Cube for semantic layer, Loops for activation, Hex for Data Exploration, Paradime Bolt for orchestration. Zero infrastructure overhead.
The Problem: Nobody Knew How They Used Our AI Features
At Paradime, we built DinoAI to power AI-driven data development. Teams were using it to write dbt™ code, debug pipelines, generate documentation. But when managers asked "what's the ROI on this AI thing?"
Users had a blindspot. Didn't know how they were using DinoAI, what it was actually helping them do, or how much time they were saving. Managers couldn't quantify the productivity impact. And we were guessing at which features mattered for our users.
As the “solo data team”, I needed to build something comprehensive but maintainable.
The goal: an end-to-end pipeline that would power customer-facing analytics, user activation and internal intelligence, all while being flexible enough to evolve with our product.
The Stack: Cloud-Native AI, Zero Infrastructure
The architecture is straightforward:
Warehouse: BigQuery
Transformation: dbt™ Core
AI Layer: Vertex AI (via BigQuery AI functions)
Semantic Layer: Cube
Orchestration: Paradime Bolt
Activation: Loops (email)
Internal Reporting: Hex
Why this works: no infrastructure to manage, native LLM execution where data lives, single semantic layer serving both internal and external use cases, and open source where lock-in would hurt us (Cube, dbt™).
Building the Data Foundation: Ingestion Strategy
We pull data from four sources, each serving a specific purpose in understanding AI adoption.
Auth0 gives us the authentication layer - who's logging in, when, from where. This matters because AI usage patterns differ across sessions. Is someone using DinoAI in a focused work session or casually exploring?
Stripe connects the money to the features. Which plans include AI capabilities? Who's on what tier? This helps us understand if AI is driving upgrades or if it's table stakes.
Segment captures every product interaction. The AI-assisted deployments, code generations, feature clicks - this is the raw material for understanding what people actually do with DinoAI.
RDS replication brings in the application database state. User profiles, account settings, project configurations. The context that makes event data meaningful.
For ingestion mechanics, we use Fivetran and dlthub for third-party sources, and PeerDB for database replication into BigQuery.
The key decision here was reliable incremental ingestion - simpler architecture, lower costs, easier to debug than real-time streaming.
Transformation: Where dbt™ Becomes the Single Source of Truth
dbt™ is where raw data becomes insight-ready. We're standardizing event taxonomy across sources, applying business logic to filter out noise and focus on meaningful interactions, creating user and team-level aggregations that power our metrics, and building the foundation for AI summarization with context-rich datasets.
The cool part? Thanks to DinoAI, a lot of this modeling could be automated. Give it the right context, and it generates SQL, adds documentation, writes tests. What would've been weeks of manual data modeling turned into days.
How to Run LLMs Directly in SQL (This Changes Everything)
This is the game-changer. Instead of managing separate AI infrastructure - training environments, model serving, APIs, the whole mess - we use BigQuery's native AI functions.
You write SQL. The SQL calls an LLM. The LLM runs where your data lives. No data movement, no API calls, no infrastructure.
Here's how we generate personalized insights at scale:
The prompt is embedded in the SQL. We pull context from our dbt™ models, feed it to the LLM, and get back personalized summaries like this:
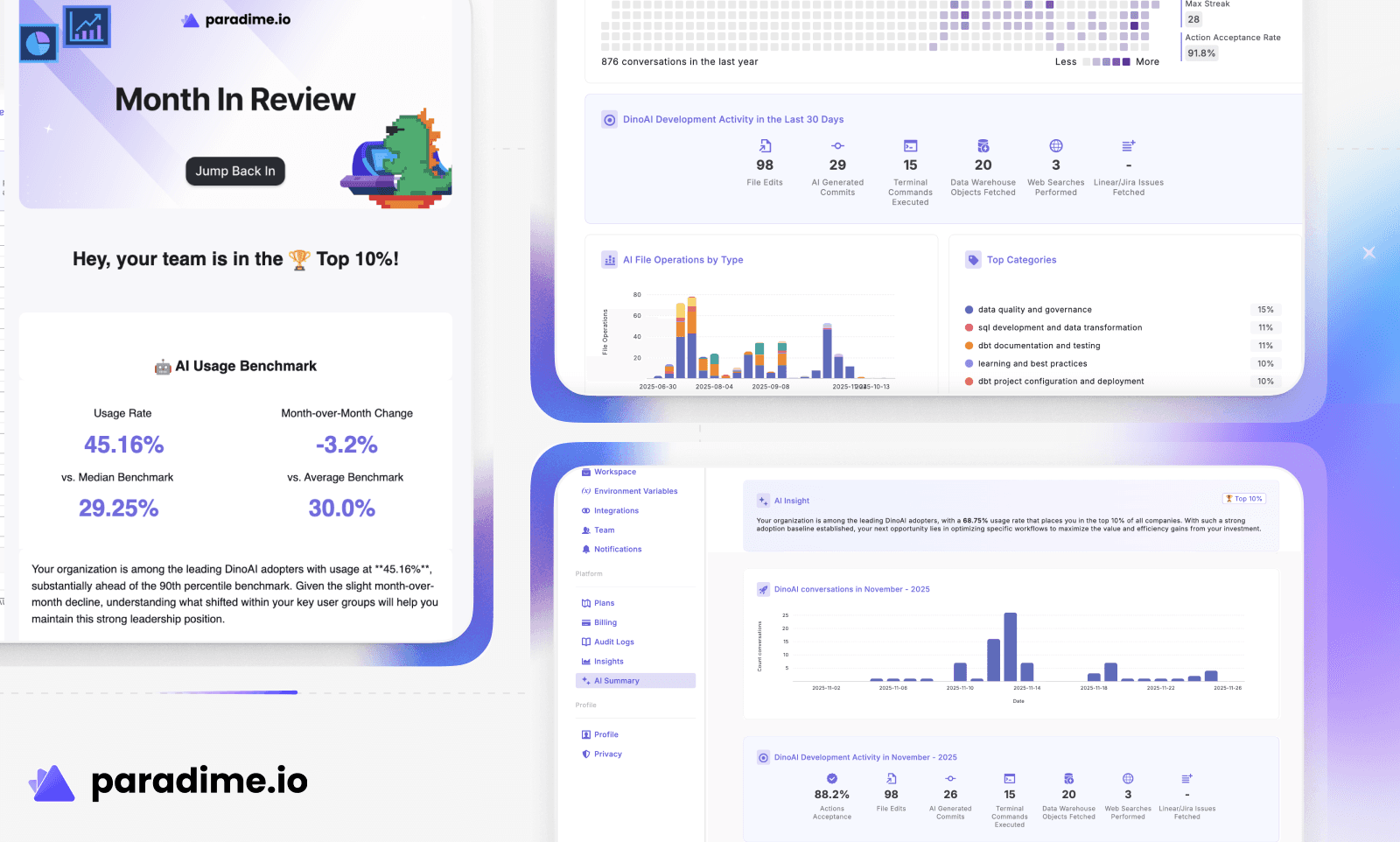
"Your organization is among the leading DinoAI adopters, with a 68.75% usage rate that places you in the top 10% of all companies. With such a strong adoption baseline established, your next opportunity lies in optimizing specific workflows to maximize the value and efficiency gains from your investment."
Feed rich context from our dbt™ pipeline directly into prompts
Generate personalized summaries at scale without managing separate ML infrastructure
Iterate quickly on prompt engineering using familiar SQL tools
The AI summaries help both teams and ourselves understand feature impact without having to manually interpret raw metrics every single time. This allows us to create curated summarization of key metrics for each of our customers at scale.
Why We Chose Cube for the Semantic Layer
Cube solved a critical problem: metric consistency across internal and external use cases.
Why Cube:
True open source - control over our semantic layer without vendor lock-in. Critical for infrastructure this important.
Multiple API interfaces - GraphQL, REST, and SQL APIs. Dashboard uses GraphQL, Hex queries via SQL - same metric definitions.
Environment management - separate dev and prod. Test changes before they hit production when connecting Paradime.
Observability - when exposing metrics externally, we need visibility into:
Which metrics are slow
What's cached vs. computed fresh
Where we need pre-aggregations
Query patterns indicating optimization opportunities
Cube's query history gives us this out of the box.
Security by default - row-level security ensures accounts only access their own data. No complex application logic - baked into the semantic layer using query rewrite and security context.
Clean infrastructure - runs alongside our existing stack. Scale up or down without DevOps overhead.
From dbt™ to Cube with DinoAI
One challenge: translating dbt™ models into Cube's semantic definitions. Different syntax, different mental model.
DinoAI accelerated this. It helped extend dbt™ models into Cube views and metric definitions. What could have been weeks of manual work turned into days from zero to production.
BigQuery + Vertex AI: The GCP Advantage
We chose BigQuery not just as a warehouse, but as an AI execution environment.
The GCP ecosystem advantage:
Unified platform with storage and compute
Native Vertex AI integrations
GCP's Model Garden for flexibility with LLMs
No infrastructure management
Iterate quickly on best models for use cases
Native AI functions: This is the secret sauce. Using BigQuery's AI.GENERATE_TEXT and other LLM functions, we run AI transformations directly in SQL. Check my previous post on what BigQuery enables with other AI Functions with AI.SCORE, AI.If, and AI.CLASSIFY
Activating Insights: Getting Data to Users
Having insights is worthless if they don't reach users. We built an activation pipeline using Poetry and Python that:
Queries the metrics and insights we generated
Formats personalized reports for each user and team
Sends emails via Loops with monthly and weekly summaries
This runs on a schedule using Paradime Bolt. Users get in-app summaries of their DinoAI usage, monthly reports highlighting trends and achievements, and actionable insights on underutilized features that could boost productivity.
Why Loops? We chose Loops for email delivery because it's purpose-built for product teams sending transactional and lifecycle emails. Unlike generic email services, Loops offers:
Developer-friendly API that integrates seamlessly with our Python pipeline
Built-in contact management that automatically handles user properties and segmentation
Audience filtering so we can easily target specific user cohorts without complex logic
Email analytics to track opens, clicks, and engagement right in the platform
Reliable deliverability without the overhead of managing our own email infrastructure
Intuitive email composer that feels like working in Notion—crafting beautiful, on-brand emails is a breeze with their block-based editor
The Python approach gives us maximum flexibility. Want to A/B test messaging? Done. Customize based on user segments? Easy. And Loops handles the email infrastructure, so we can focus on crafting insights that actually drive user activation.
Orchestration: Keeping Everything Running
A pipeline is only as good as its orchestration. We use Bolt, Paradime's CI/CD and scheduling engine, to manage two jobs:
Job 1: Daily Data Sync and Transformation
Triggers Fivetran sync - pull fresh data from Auth0, Stripe, other sources
Runs dbt™ transformations - snapshots for SCD tables, usage metrics, prep data for LLM context
Executes BigQuery AI functions - generate personalized summaries per customer
Bolt's command settings orchestrate the entire pipeline end-to-end. Metadata monitoring, alerting to Slack/Teams, email built in.

Job 2: Data Quality and Email Activation
Tests data for Loops campaigns using dbt™ tests
Validates AI-generated summaries - ensure quality standards
Triggers Loops API - send personalized monthly reports
Command settings in Bolt chain steps with error handling. Data quality tests fail? No emails sent. Team gets Slack alert. Prevents sending incomplete or incorrect insights to customers.
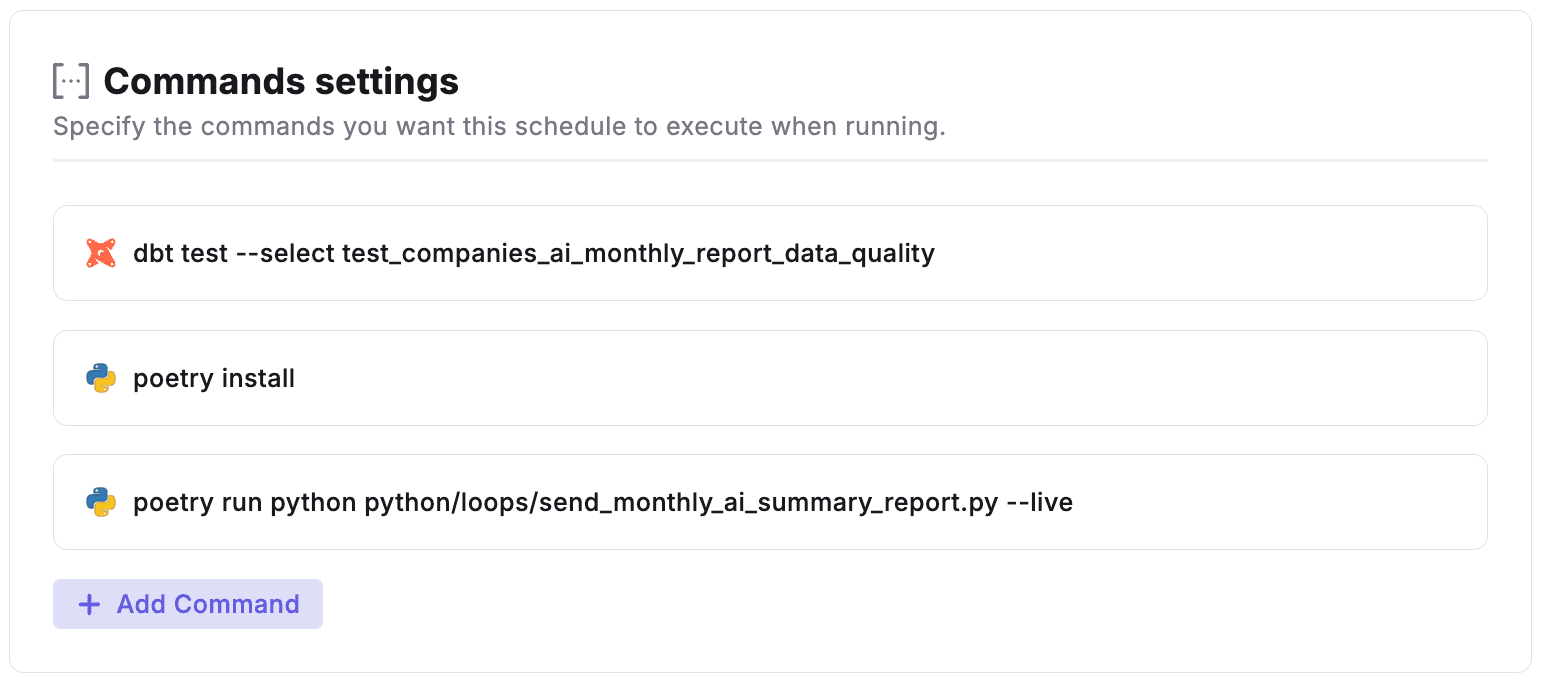
Why Bolt for orchestration?
No infrastructure management
Integrates with Fivetran, Airbyte, dlthub for ingestion
dbt™ commands for transformation
Python support for everything else
Triggers Power BI, Tableau, Hex for automated refresh
Works with Hightouch and Census for reverse ETL
Logs, monitoring, alerts without external tools
Bolt's DinoAI agent helps decipher run logs and reduce MTTR
Internal Intelligence: Hex for Analytics
While customers see polished dashboards, we needed exploratory analytics internally. Hex was perfect:
Notebook experience - experiment, pull data, explore fast.
Cube integration - connects directly to Cube. Internal reports use exact same metrics we serve customers. Single source of truth, no drift.
Speed of iteration - answer "which AI features drive adoption?" in minutes, not days.
SQL, Python, visualizations in one environment. Invaluable for understanding feature performance as we release.
Here's What Works
1. Start batch, go real-time only if needed
Most analytics don't need sub-second latency
Batch is simpler, cheaper, easier to debug
We run daily syncs - works perfectly
2. Use cloud-native AI when possible
BigQuery ML, Snowflake Cortex, Databricks AI
Avoid building separate ML infrastructure
Run models where data lives
3. Semantic layer is non-negotiable
Single source of truth for metrics
Prevents drift between internal and external reporting
Makes exposing metrics externally safe
4. Observability matters for customer-facing metrics
Monitor query performance
Track cache hit rates
Identify slow queries before customers complain
Cube's query history handles this
5. AI agents accelerate infrastructure work
Used DinoAI to extend dbt™ models into Cube
Wrote Python scripts for Loops workflow
Infrastructure-as-code is infrastructure-with-AI-assistance
The Impact: What This Pipeline Powers
Customer dashboards - teams see how AI transforms workflows, with personalized summaries making data actionable.
Product intelligence - informs every feature decision. We know what works, what doesn't, where to invest.
Activation campaigns - drive engagement by showing users value they're getting (and missing).
Internal reporting - keeps leadership aligned on AI adoption trends and business impact.
Key Learnings from Building This Solo
Building this pipeline as a solo data team taught me that modern data tools hit an inflection point. What would've required five engineers five years ago is now doable by one person with the right stack and AI assistance.
Start with questions, not tools. We began by defining what insights mattered, how we wanted to use it, then chose tools to answer them. Not the other way around.
Semantic layers prevent chaos. As soon as you serve metrics both internally and externally, invest in a proper semantic layer. We chose Cube because it's open source and feature-rich.
Batch is effective. Real-time is expensive and complex. Most analytics don't need it. Daily (or higher frequency) batch runs work perfectly for this use case.
Observability isn't optional. Serving external users? You need deep visibility into query performance. Cube's monitoring has been essential.
At Paradime, this architecture transformed how we understand AI adoption - both for customers and internally. And we did it without a data engineering team.
The tools are there. The infrastructure is simpler. AI helps with the heavy lifting. What you need is a clear goal and the right stack to get there.
FAQs
What's the best way to run LLMs on data warehouse data?
Use native AI functions in your warehouse. BigQuery's AI.GENERATE, Snowflake's Cortex, Databricks' AI Functions. No data movement, no API calls, no infrastructure overhead.
How do you build a semantic layer for customer-facing analytics?
Use Cube. It gives you:
Multiple API interfaces (GraphQL, REST, SQL)
Row-level security out of the box
Query monitoring and caching
Environment separation for dev/prod
Critical for serving metrics externally without chaos.
What tools do you need to build AI analytics pipelines?
Minimum stack:
Data warehouse (BigQuery, Snowflake, Databricks)
Transformation layer (dbt™)
Orchestration (Paradime Bolt, Airflow, Dagster)
Optional but recommended: Semantic layer (Cube)
Conclusion
Modern data tools hit an inflection point. What required five engineers five years ago? One person, right stack, AI assistance.
Choose tools that integrate naturally, provide leverage through AI and automation, scale without operational burden, and keep you close to data without drowning in complexity.
At Paradime, this architecture transformed how we understand AI adoption - for customers and internally. No data engineering team required.
Want to see how Paradime helps data teams ship faster with AI? Try paradime.io


