DinoAI v3.0: The ADE-Bench Report
38 of 43 tasks resolved. 254 of 258 tests passed. First place overall — ahead of the team that built the benchmark.

Kaustav Mitra
·
7
min read

When we started building DinoAI v3.0, we made a bet: that a specialist data engineering agent, given the right context and the right tooling, could decisively outperform general-purpose coding agents on real analytics work.
This report is the result of testing that hypothesis against the hardest public benchmark we could find — and then publishing every number, every failure, and every link so you can verify it yourself.
The headline result
On dbt Labs' ADE-Bench — a 43-task, 258-test benchmark of real-world analytics engineering challenges — Paradime DinoAI with Claude Sonnet 4.6 resolved 38 of 43 tasks (88.37%) and passed 254 of 258 individual tests (98.45%).
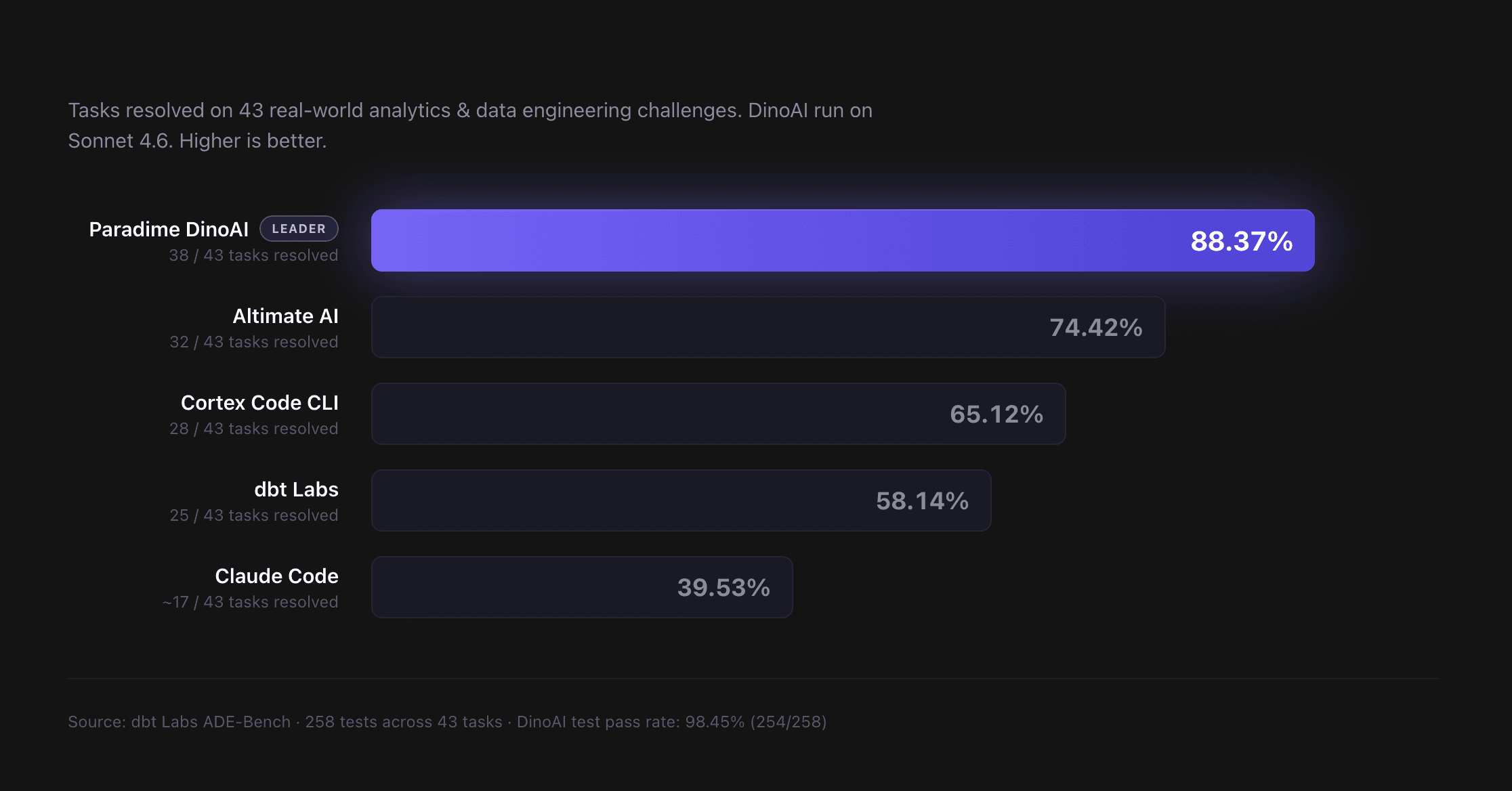
System | Tasks Resolved | Score |
|---|---|---|
Paradime DinoAI (Sonnet 4.6) | 38 / 43 | 88.37% |
Altimate AI | 32 / 43 | 74.42% |
Cortex Code CLI | 28 / 43 | 65.12% |
dbt Labs (ADE-Bench team) | 25 / 43 | 58.14% |
Claude Code (baseline) | 17 / 43 | 39.53% |
Benchmark run: April 1, 2026. Sources and raw data are linked in the Reproducibility section below.
What is ADE-Bench?
ADE-Bench is a public benchmark created and maintained by dbt Labs to measure how well AI agents perform on real analytics engineering tasks. Unlike toy coding benchmarks — write a function, pass a couple of unit tests — ADE-Bench is designed to reflect the messiness of actual data work: operating inside an existing codebase, reasoning over multiple models and their dependencies, handling schema changes, and producing changes that pass an integration test suite.
The benchmark spans (at the time of testing) 43 tasks across 8 real-world domains:
Domain | Tasks | What it tests |
|---|---|---|
airbnb | 9 | Marketplace data modeling, listing/booking joins |
analytics_engineering | 8 | Core dbt patterns and refactoring |
asana | 5 | Project tracking and aggregation |
f1 | 11 | Motorsport analytics, time-based aggregations |
intercom | 3 | Customer support data, conversation threading |
quickbooks | 4 | Accounting and financial modeling |
simple | 2 | Minimum-viable transformations |
workday | 1 | HR data handling |
Each task ships with a set of integration tests — 258 tests in total across the 43 tasks. A task is marked resolved only if the agent's final code passes every single test. Partial credit isn't a thing. If one test fails, the whole task is unresolved.
That makes ADE-Bench a hard, honest benchmark. There's no hiding behind "mostly right" — either the pipeline works end-to-end, or it doesn't.
How to read the results
Two metrics, two different things they tell you.
Tasks resolved is the headline metric. It measures how many of the 43 tasks the agent shipped correctly. DinoAI resolved 38 of 43, which is 88.37%.
Test pass rate is a more granular view. It counts individual tests across all 258 tests in the benchmark. DinoAI passed 254 of 258, which is 98.45%.
That gap between 88.37% and 98.45% is worth pausing on. It tells you something important about how DinoAI fails: when it fails, it fails tight. On the tasks DinoAI didn't resolve, it was typically one or two tests shy of a full pass — not catastrophically wrong. In the 5 tasks marked unresolved or skipped, DinoAI still passed 12 of the 26 tests they contained. That matters because in real-world data engineering, "90% of the way there" is reviewable. "Completely off the rails" isn't.
Category breakdown: where DinoAI shines, where it struggles
Category | Tasks | Resolved | Pass Rate |
|---|---|---|---|
airbnb | 9 | 9 | 100% |
analytics_engineering | 8 | 8 | 100% |
asana | 5 | 5 | 100% |
quickbooks | 4 | 4 | 100% |
simple | 2 | 2 | 100% |
f1 | 11 | 8 | 72.7% |
intercom | 3 | 2 | 66.7% |
workday | 1 | 0 | 0% |
DinoAI went 5-for-5 on the categories that represent the bulk of day-to-day analytics engineering work: marketplace data, core dbt patterns, project tracking, financial modeling, and basic transformations. On the 28 tasks across those five categories, DinoAI resolved all 28.
Where did it struggle? Motorsport analytics (f1) and customer support data (intercom). Both categories involve complex time-based aggregations, multi-table joins with ordering edge cases, and domain-specific conventions that pushed the agent's reasoning harder. And we were unable to complete the workday category due to an environment issue during the benchmark run — more on that below.
The failures, in detail
No hedging, no spin. Here's exactly what went wrong on the 5 tasks DinoAI didn't resolve.
f1002 — 9 of 10 tests passed.
A multi-model stats aggregation over an F1 driver career dataset. DinoAI's final models passed 9 of 10 tests; one schema mismatch in the most_podiums model caused the final test to fail. The work was almost entirely correct — it produced accurate data values for all 20 ranked drivers, but included extra breakdown columns (p1, p2, p3) that the spec did not ask for. The equality test compares column schemas before comparing data, so the additional columns caused an immediate schema mismatch failure even though the underlying numbers were perfect.
f1006 — 2 of 4 tests passed.
DinoAI passed 2 of 4 tests. Both equality tests failed due to a single logic error: SUM(points) was used on standings tables that store cumulative season-to-date totals, not per-race points. This caused every row in constructor_points and driver_points to be inflated ~10–12× (e.g. Red Bull 2023: 10,158 pts instead of 860). The tables were built and populated correctly — the data just held the wrong numbers. The fix is a one-word change per model: SUM → MAX.
f1008 — skipped.
This task does not include a meaningful reference output for validation. The solution seed is a placeholder (foo) rather than a real expected result for the constructor models. Because we cannot reliably verify whether the task was completed correctly, we chose not to run it. Rather than reporting a misleading pass or fail, we marked it as skipped.
intercom003 — 1 of 2 tests passed.
The model was built correctly — all 19 columns, correct logic, correct values. The test failed due to a data mismatch on the primary key (conversation_id), caused by a bug in the benchmark's own answer key.The benchmark's expected output stored conversation_id as a 32-bit integer. The actual source IDs are 15-digit numbers (156643300001311) that silently overflow a 32-bit integer, producing a completely different value (300001311). DinoAI's model used the correct full-length IDs from the source data — but those didn't match the overflowed values frozen into the answer key.
workday001 — skipped (9 tests).
This task is an incomplete stub and was not run in the benchmark. The prompt instructs the agent to do nothing, and the solution seed is a placeholder (foo) with no real expected output. There is no meaningful work to evaluate or validate. Rather than reporting a misleading result, we marked it as skipped. The task needs a proper prompt, a well-defined goal, and a real ground-truth seed before it can be included in a future benchmark run.
If you want to get strict about it — excluding the two tasks skipped for environment reasons — DinoAI's "effective" task resolution rate is 3 failures out of 41 eligible tasks, or 92.68%. We're reporting the full 88.37% number anyway because environment issues are part of the job, and we'd rather undersell than oversell.
Why DinoAI wins (and why generalist agents lose)
Here's the part that should catch your attention.
The same frontier model — Anthropic's Claude Sonnet 4.6 — is powering both Claude Code (39.53%) and DinoAI (88.37%) in this benchmark. Same underlying model. 49-point gap in task resolution.
How does identical model intelligence produce such different results? Three reasons.
1. Context graph, not context dump
Claude Code, when given access to a codebase, treats every file as roughly equal weight. Point it at a large repo and it'll grep, read, and pull context across files without strong priors about which ones matter for the task at hand. It works, but it's expensive and it dilutes reasoning on harder tasks.
DinoAI builds a context graph during setup. It understands the dependency relationships between models, which ones feed which, which tests guard which pipelines, which lineage edges matter for which transformations, and which docs correspond to which business logic. When you ask DinoAI to fix a schema change, it doesn't grep the whole repo. It walks the dependency graph, identifies exactly the models affected, pulls only the relevant tests, and operates on a targeted context window.
The practical result: DinoAI uses a fraction of the context Claude Code would use for the same task, and the context it does pull is directly relevant to the work.
2. Multi-model routing
DinoAI doesn't use one model for everything. Reasoning-heavy work (planning multi-step refactors, debugging complex failures) goes to Claude Opus. Straightforward SQL edits and targeted file changes go to Haiku. Structured intermediate steps go to Sonnet.
Generalist agents run every task through the same frontier model. That means you're either overpaying for simple tasks (burning Opus tokens on a rename) or underpowering hard ones (forcing Haiku to reason through a multi-model refactor). DinoAI routes per-task, which lets it spend reasoning budget where it actually matters.
3. A specialist test loop
When DinoAI starts a task, it spins up an isolated sandbox, clones the relevant code, wires up the correct warehouse schema, and lineage context, makes its changes, and iterates running the dbt™ CLI until they pass — or until it can explain why they won't.
Claude Code can do this if you prompt it carefully and wire up the right tool access. But it's not the default loop. For DinoAI, it's the only loop. Every single task starts with "what does the data problem look like?" and ends with "do the tests pass to solve the problem at hand?" That's an enormous alignment advantage on a benchmark whose entire scoring criterion is "did the tests pass?"
The kicker: we beat dbt Labs on their own benchmark
dbt Labs built ADE-Bench. They designed the tasks, wrote the test suites, and know the benchmark intimately. They also ran it themselves and published the results.
dbt Labs' own ADE-Bench score: 58.14% (25 of 43 tasks resolved).
Paradime DinoAI's score: 88.37% (38 of 43 tasks resolved).
We beat the team that built the benchmark by more than 30 points on their own test.
We're not flagging this to be smug — we're flagging it because it's the strongest stress test a benchmark can get. When the team that designed a test performs worse than an outside contestant, you're looking at one of two possibilities:
The contestant has genuinely better tooling for the task.
The test is gameable and the outside contestant optimized for the test itself.
ADE-Bench isn't gameable. It's a public, versioned benchmark with real integration tests that you either pass or you don't. Which means the gap between DinoAI and dbt Labs reflects real tooling advantages — the context graph, the multi-model routing, the sandboxed test loop we just walked through above.
And to be clear: we have enormous respect for dbt Labs. They built the tool that defined the modern analytics engineering workflow. They built the benchmark we're using to measure our own work. And they ran that benchmark honestly and published their own score — a move very few companies would have made. We're reporting our delta because the community deserves to see both numbers side by side.
Reproducibility
A benchmark only matters if you can reproduce it. Here's everything you need to verify our results independently.
Our raw data
Every task, its status, test counts, and the per-test pass/fail breakdowns are available as CSV.
Competitor benchmark sources
We're publishing the exact URLs for every competitor's own benchmark page. Go read them. We'd rather you compare the full context than take our word for it.
System | Source |
|---|---|
Altimate AI | |
Cortex Code CLI | |
dbt Labs | |
Claude Code | Baseline run of Anthropic Claude Code against the same task set with no custom tooling |
How to run ADE-Bench yourself
ADE-Bench is publicly maintained by dbt Labs. Clone the repo, configure the agent of your choice, and run the test harness against the 43 tasks. If you run it and your numbers differ from ours, email us — we want to understand why.
Our commitment
We will re-run this benchmark every month, and we will publish the updated results regardless of whether DinoAI's lead shrinks or grows. If a new frontier model ships, we re-run. If a new competing agent ships, we re-run. Transparency is the only way this kind of benchmarking stays useful for the community.
What's next
A few things already on the roadmap:
Monthly re-runs of the full ADE-Bench suite against the latest frontier models and competing agents. We'll publish every run.
Category-specific deep dives — starting with a full write-up of how DinoAI handles the f1 category and what it would take to close the gap on motorsport-style time-series aggregations.
Expanding to additional public benchmarks as they emerge in the data engineering agent space. ADE-Bench is the best public benchmark we have today, but we expect more to appear, and we want DinoAI measured against all of them.
Try it yourself
ADE-Bench measures what DinoAI can do on a standardized test. What matters for your team is what it can do on your data, your workflows, and your backlog.
We're running a 30-day open beta of DinoAI v3.0 starting today. No usage limits. No seat charges. No long-term commitment. Connect your warehouse, your repo, and your Slack workspace, and see what an 88.37%-on-ADE-Bench agent can do against your real tickets.
Read the DinoAI v3.0 launch announcement →
Questions about methodology, the raw data, or reproducibility? Email benchmarks@paradime.io. We read every message and we'll answer technical inquiries in detail — especially from anyone attempting to reproduce the benchmark independently.


