Paradime Bolt vs dbt Cloud™ jobs
See which platform handles mission-critical dbt™ pipelines better: AI debugging, global scheduling, enterprise integrations & 100% uptime

Parker Rogers
·
7 minutes
min read

Most analytics engineering teams start the same way: a few dbt™ models, basic dbt Cloud™ scheduling, maybe some simple cron configurations. It works fine when you're small, your pipelines are straightforward, and downtime doesn't immediately impact business operations. But as your data stack becomes mission-critical and your team scales globally, those basic orchestration tools become the bottleneck that creates operational stress and pipeline reliability issues.
The breaking point usually hits during a weekend incident. Your dbt™ pipeline has failed, you're parsing through generic error logs trying to understand what went wrong, and you realize your notification system only tells you that something failed—not what failed or how to fix it. Meanwhile, executives are asking when their Monday morning dashboards will be ready.
In our latest Paradime vs dbt Cloud™ livestream, we demonstrated how modern data teams are moving beyond basic scheduling to sophisticated orchestration that actually supports enterprise-grade production needs. From AI-powered debugging to timezone-aware scheduling and enterprise integrations, these capabilities represent a fundamental evolution in how teams manage production dbt™ workloads.
The Production Orchestration Gap
Traditional dbt™ orchestration tools focus on the basics: running commands on a schedule and sending notifications when jobs complete or fail. But production teams need far more sophisticated capabilities to maintain reliable, scalable data operations.
Paradime's Bolt orchestrator excels in scheduling flexibility, offering both UI-based schedules for rapid deployment and code-based configurations for regulatory compliance and GitOps workflows. This dual approach becomes crucial as teams grow and face enterprise requirements that basic scheduling cannot accommodate.
Beyond basic scheduling, production teams need intelligent monitoring that prevents incidents before they impact stakeholders. SLA threshold alerts represent this proactive approach—teams can define expected completion times for each job individually, receiving immediate notifications when pipelines exceed their normal runtime rather than waiting for complete failures.
This proactive monitoring prevents the common scenario where teams discover failed jobs hours after they occur, often when stakeholders start asking about missing data.
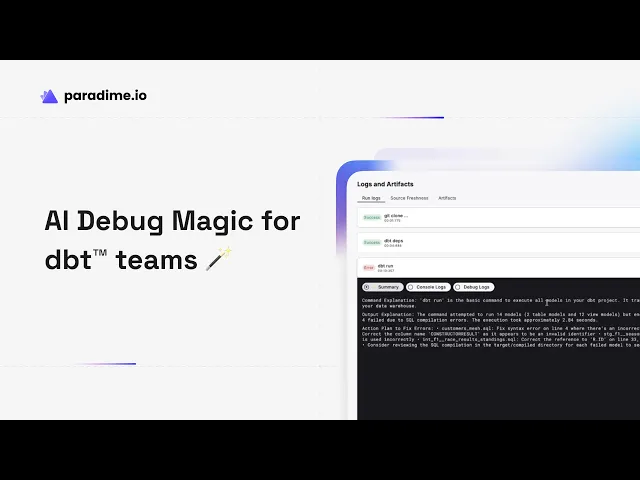
But the real breakthrough comes with Paradime's AI-powered debugging capabilities. Instead of parsing hundreds of lines of console output during incidents, teams get human-readable summaries with specific remediation steps: "There's an invalid column reference in your staging model. Check line 15 where 'customer_id' is referenced—this column doesn't exist in the source table."
"We provide a direct action plan on what to do in case of a failure with suggestion of what to fix," explains Fabio. "Think about for when you have that engineer that is on call. Time is important if something fails on a Saturday or a Sunday over the weekend."
This transforms on-call responsibilities from requiring deep dbt™ debugging expertise to following clear, AI-generated instructions that any team member can execute.
Beyond dbt™: Comprehensive Workflow Orchestration
Modern analytics workflows extend far beyond dbt™ transformations. Teams need to orchestrate the entire data lifecycle: Python ingestion scripts before dbt™ runs, BI dashboard refreshes after transformations complete, reverse ETL syncs to operational systems, and integration with monitoring tools throughout the process.
"We support python commands and external commands like refreshing Power BI dashboards or Tableau worksheets," demonstrates Fabio during the livestream. This comprehensive approach eliminates the need to coordinate multiple tools for end-to-end data workflows while maintaining visibility into the entire pipeline.
Enterprise-Grade Integrations and Incident Management
As data systems become more central to business operations, pipeline failures need structured incident response rather than ad-hoc firefighting. Paradime integrates natively with enterprise tooling to ensure failures automatically generate trackable incidents with appropriate context.

"When we look at ticketing, part of managing errors in our pipeline, we can set up Jira or Linear or Azure to receive an event and create a Jira ticket or linear issue every single time there is a job failing," demonstrates Fabio. This automation ensures that production issues are immediately visible to the appropriate teams with relevant debugging context and historical tracking.
The integration ecosystem extends beyond ticketing to comprehensive observability. Native connections with PagerDuty, Datadog, New Relic, and incident.io provide teams with enterprise-grade monitoring that treats data pipeline reliability as seriously as application uptime.
The Architecture Advantage: Built for Production Scale
The foundation of reliable orchestration starts with architecture designed for production workloads rather than retrofitted development tools. Paradime's Bolt is built from the ground up using battle-tested infrastructure like Kubernetes, delivering measurable reliability improvements over traditional solutions.
This architectural approach produces concrete results: 100% uptime in the last 90 days compared to competitors who struggle to maintain 99% reliability. For teams running mission-critical data pipelines, this reliability difference compounds over time—some customers haven't experienced a single outage in over 365 days.
The last recorded incident was in October 2023, lasting just 40 minutes. This track record becomes increasingly important as data systems support real-time business decisions where pipeline reliability transitions from technical nice-to-have to business-critical capability.
From Reactive to Predictive Operations
The evolution from basic scheduling to sophisticated orchestration represents a fundamental shift from reactive to predictive data operations. Modern teams can identify and resolve issues during execution, often before stakeholders notice degraded performance.
"Error resolution time in Paradime i.e. the Mean Time to Repair (MTTR) is 70% less compared to other solutions in the market," explains Kaustav. "That's because the moment you recognize a failure, you are able to get to a fix much faster."
This operational maturity becomes increasingly important as data systems support real-time business decisions. When executives rely on dashboards fed by your dbt™ models for daily operations, pipeline reliability transitions from technical nice-to-have to business-critical capability.
The Compound Effect of Production Excellence
The true power of modern orchestration isn't in any single feature—it's how capabilities compound to create operational excellence. AI-powered debugging that provides instant resolution steps, timezone-aware scheduling that supports global teams, enterprise integrations that automate incident response, and predictive monitoring that prevents issues before they impact stakeholders.
This compound effect explains why teams report dramatic improvements in operational efficiency and reliability. It's not just about running dbt™ commands faster—it's about eliminating entire categories of operational overhead while enabling focus on high-value analytics engineering work.
Ready to Transform Your Production Operations?
If your team has outgrown basic dbt™ scheduling and manual incident response, modern orchestration platforms offer a clear evolution path. From AI-powered debugging to enterprise-grade reliability guarantees, these capabilities transform data operations from a source of operational stress into a competitive advantage.
The future belongs to teams that can reliably deliver data products at scale while maintaining the agility and productivity that makes analytics engineering effective. Paradime's Bolt orchestrator provides the foundation for this operational maturity.
Explore how Paradime's Bolt can revolutionize your production dbt™ workflows and reduce your mean time to repair by 70%...for free!


